This case shows the possibility to discover network problems via
monitoring of available bandwidth. Our experimental monitor ABwE is running
24 hours a day. It is using Packet-pair dispersion techniques to
analyze ABW
(available Bandwidth) on selected paths. We are sending only 20 packet-pairs
probes. So it means that ABwE doesn't generate large amounts of network
traffic and it is totally
non-intrusive. The current mode is set to run 1 measurent to each host per
120 seconds. More details about ABwE can be found in the following
publication.
NERSC case - April 30th - May 1st 2003
The following paragraphs describe the situations between April 30th and
May 1st, 2003 when the people at NERSC started to heavily use
the host pdsfgrid02.nersc.gov that we are monitoring from SLAC by
ABwE and also by
IEPM-BW.
Our ABwE monitor immediately discovered very dramatic bandwidth changes and
also other tools which we are using for monitoring reported unusual situations.
The iperf monitoring tool reported
variable ping Round
Trip Times (RTT), increasing from 2 ms to hundreds of ms,
and lower throughput dropping from from
a standard 550 Mbits/s
to 350 Mbits/s.
At the same time we were also monitoring a
second host,
pdsfsu00.nersc.gov, at NERSC by IEPM-BW and this
showed
no changes in iperf measured throughput or RTT.
We verified the ping losses manually running
from SLAC to the two NERSC hosts.
----pdsfgrid2.nersc.gov PING Statistics----
69 packets transmitted, 67 packets received, 2% packet loss
round-trip (ms) min/avg/max = 2/67/1030
----PDSFSU00.NERSC.GOV PING Statistics----
66 packets transmitted, 66 packets received, 0% packet loss
round-trip (ms) min/avg/max = 2/2/2
Strangely (since pings are round trip), pings from pdsfgrid2.nersc.gov to
flora02.slac.stanford.edu did not show the burstiness of pings seen in the
reverse direction.
--- flora02.slac.stanford.edu ping statistics ---
111 packets transmitted, 97 packets received, 12% packet loss
round-trip min/avg/max/mdev = 2.031/2.458/4.242/0.389 ms
We verified that the
traceroutes from SLAC to the two hosts at NERSC
only differed at the last hop. We also measured the
RTTs and losses
to each hop along the route. This indicated that the losses were
occuring on the last hop to pdsfgrid2.
Explanation
What did really happen? No reason for panic. By logging onto
pdsfgrid2 we observed, using top that a user had started a process,
called drmServer. The drmServer is a special tool for
intensive parallel data transfers to discs.
In this case drmServer was being used for data tranfer from BNL
and then subsequently
storing these files in HPSS at NERSC.
The refence to this tool can be find at
http://www.rhic.bnl.gov/RCF/UserInfo/Meetings/Technology/Eric_Hjort_MRM.pdf.
As this document says, it performs parallel data transfers using the
gridFTP protocol
and it is used to work with data in order TBytes.
Roughly after 16 hours the abnormal situation finished and after 12:30pm
(May 1st) everything returned to normal.
The bottleneck capacity analysis returned to 622Mbits/s and the
Available bandwith to 420 Mbits/s. The Iperf again shows the expected
values.
The effects of running drmServer on the measured ABwE bandwidth estimates
is documented in the following
graphs .
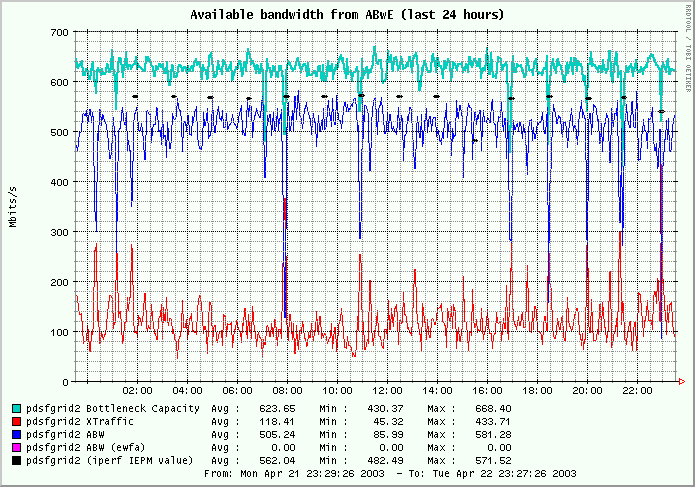
For a better understanding of this case we will also describe
the normal situation
as it looks like during previous days. The green line
represents "DBC - Dominating Bottleneck Capacity and the Blue line the
ABW - Available bandwidth value as it is reported by ABwE. The DBC is on the
level of the real capacity (622 Mbits/s) in most of the 24 hours. The ABW is
on the level 500 Mbits and similar values are seen in the iperf measurements
(black bars).
The individual drops (or complementary peaks in cross-traffic) usually are
correlated with
temporary higher
load caused by IEPM measurements (iperf,bbcp,bbftp,etc) on this path.
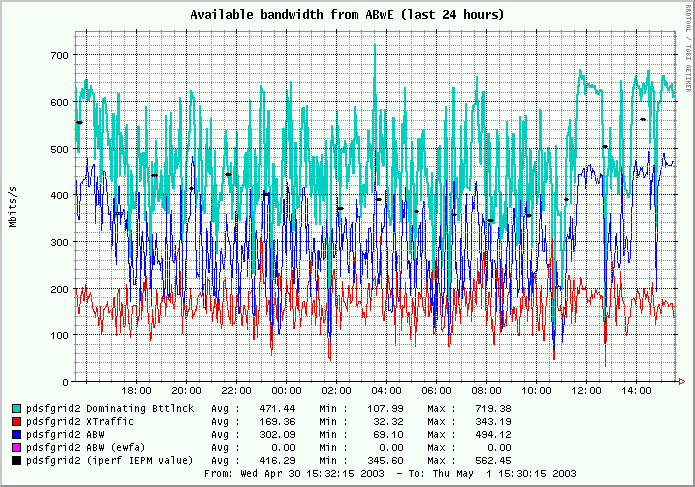
The second picture shows the unusual situation
described in the begining of this
page. The graph is "more noisy", the dispersion of the measured vaulue is quite
high. According to our experiences with the ABwE monitoring this is a typical
case when the heavy traffic on the local network dramatically hits the local
communication subsystem (CPU, NIC and also including local switch).
It has no direct relation to the path bandwith. We have seen this effect
on several other cases in the past. The common feature to all these cases
is an
utilization of NFS or AFS subsystem which locally overloads our target
machine or its network.
From the graph, you can see that the 16 hours long task finished at about
11.30 and the measurements achieved again the expected values.
Another Example (ANL)
Another example of such an impact of LAN traffic on measured WAN throughput
can be seen on our target host at ANL.
After some effort we discovered that there is a job that regularly runs
and generates at about 2000 new files with total capacity at about
23 MBytes and writes them onto disc at ANL via NFS. This target
host has a standard ANL configuration, so the users have home directories
on non-local discs mounted via NFS. The host has a 1Gbps NIC, so there are no
througput problems at the host (from the user point of view).
The job runs via cron each hour. So you can see the total network load as large
drops in the throughput from SLAC to ANL.
NFS at ANL
This generates nice graph and we can be inspired that we can see all traffic
and detect the influence of the NFS loads.
but it also demonstrate how improperly selected
target hosts can create misleading information about the path capabilities.
Example where path capacity changed
To complete this case we should illustrate how the ABwE can recognize
both a situation
that represents long term increasing cross traffic in the path or
a situation where there is a real changes in the path capacity.
Usually the measured values have not so
high dispersions as in the previous examples.
An example of a long-term increase in cross-traffic
on a path is seen here .
An example of where the physical capacity of the bottleneck bandwidth
of the path changed was when the SLAC route
to CERN changed as a result of the experimental DATATAG transatlantic line
(Chicago to CERN) being unavailable.
A backup path to CERN was created via Nordunet.
The capacity of this new path was, according to the ABwE, only 100 Mbits.
The capacity drop can be seen from
this graph from March 13th.
Iperf measurements showed during this time only 4 Mbits/s throughput.
The problem was fixed after 4 days ,
see return March 17th when a new route from Chicago-Geant-CERN replaced
backup connection.
Page owner: Jiri Navratil

{kind=link}
{kind=link}