|
|
Problems with performance between hosts on SLAC farms
Les Cottrell Page created:
December 14 '02, last update December 14, 2002.
|
As part of this Bill Weeks ran
fping
between 30 hosts (full mesh) on the farm.
To simulate the application he ran 4 packets in 4 seconds. If there was a
failure then he ram 40 packets over 40 seconsd. Though he saw failures in
the first 4 pings the next 40 (if ran) were always successful.
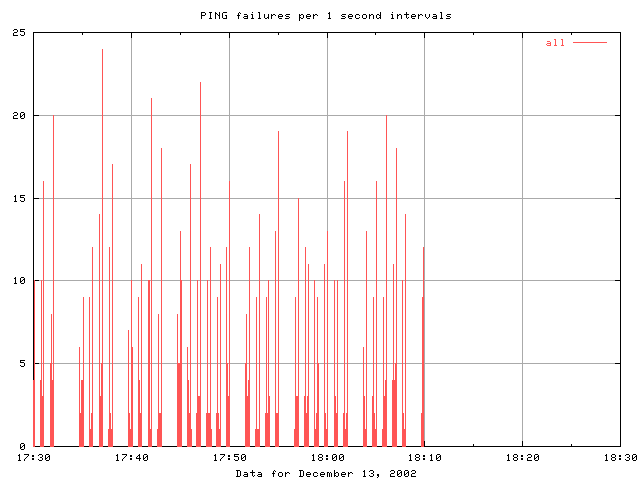
Results form Bill can be seen below. It is apparent that there are
bursts of losses
(about 25-30 seconds long) usually separated by about 30 seconds.
Occasionally a loss burst appears to be missing. It all stops after about
18:10 December 13, 2002.
3cottrell@farmboss2:~>traceroute bronco001 traceroute: Warning: ckecksums disabled traceroute to bronco001.slac.stanford.edu (134.79.124.11), 30 hops max, 40 byte packets 1 rtr-farmcore-farm2.slac.stanford.edu (134.79.123.9) 0.388 ms 0.257 ms 0.251 ms 2 bronco001.slac.stanford.edu (134.79.124.11) 0.277 ms 0.278 ms 0.206 msI also see no loss in 3500 pings from bronco513 (134.79.120.73 on Catalyst SWH-FARM6:4/1(F-100Mb-vlan120)) to farmboss2.
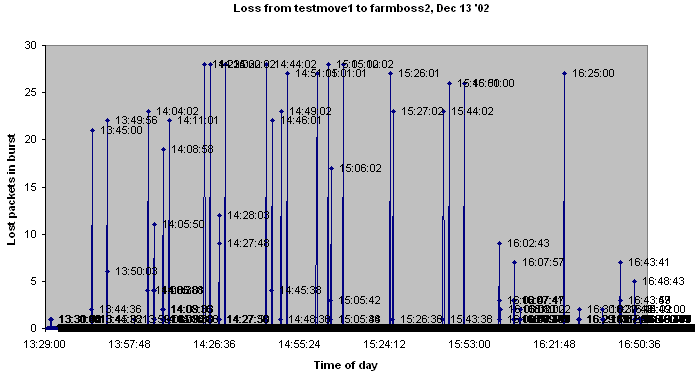
It is a very different story from testmove1 (134.79.125.41 on Cisco Catalyst switch SWH-FARM1:8/19 (F-100Mb-vlan124) on the same VLAN as bronco001) to farmboss2. Here I see 6.4% loss. The loss patterns are interesting. They come in bursts of about 28 seconds duration. Within the 28 seconds the losses may appear as every other packet lost or as a successive group of say 20 packets lost, then a packet received then a packet lost etc. The separation of the burst is between 4 and 17 minutes with a fairly flat distribution. The figures below illustrate the above. The traceroute appears as:
2cottrell@farmboss2:~>traceroute testmove1 traceroute: Warning: ckecksums disabled traceroute to testmove1.slac.stanford.edu (134.79.125.41), 30 hops max, 40 byte packets 1 rtr-farmcore-farm2.slac.stanford.edu (134.79.123.9) 0.418 ms 0.227 ms 0.217 ms 2 testmove1.slac.stanford.edu (134.79.125.41) 0.382 ms * 0.238 ms
| Time series of losses the labels are the times of the losses |
 |
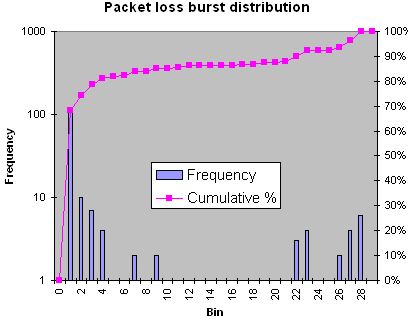
| Distribution of packet loss burst sizes |
> |
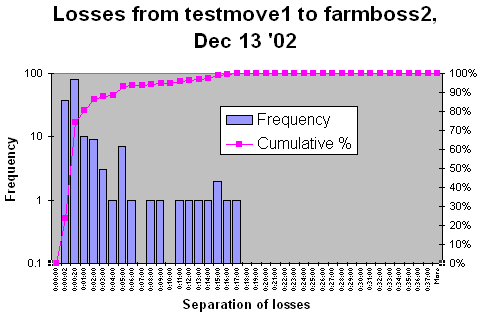
| Distribution of packet burst separations, note the x axis is non linear, the first bin is from 0-2 seconds (i.e. 1 packet seen between 2 lost packets, the second is fron 2 - 20 seconds, following that the bins are for 1 minute intervals. |
> |
Farmboss2 <-> SWH-FARMCORE:13/2 (F-1000Mb vlan 120) <-> SWH-FARMCORE:10/15 (F-1000Mb Trunk) <-> SWH-FARM1:2/2 (F-1000Mb Trunk) channeled with SWH-FARMCORE::9/15 (F-1000Mb Trunk) <-> SWH-FARM1:1/2 (F-1000Mb Trunk) <-> SWH-FARM1:18/19 (F-100Mb VLAN 124) <->Testmove1The 5 minute average load on the trunks was of the order of 200Mbits/s, see below:
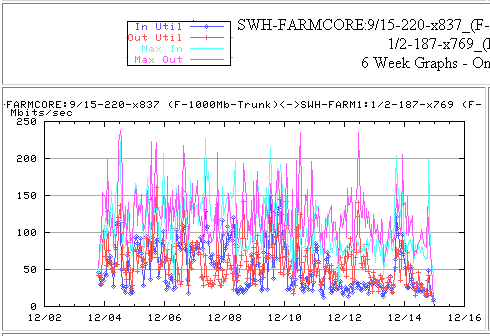
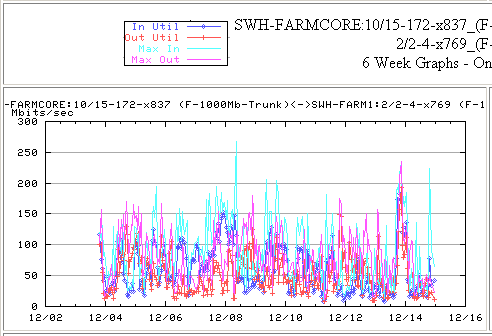
Connie Logg also noted on Dec 10 2002:
About 18:00, after I modified the 5 sec data collection to ONLY
log data if there wer packet losses, I noticed a spurt of packet losses to
# SWH-FARMCORE:4/14-123-x836_(F-1000Mb-Trunk)<->SWH-FARMCORE2:2/2-203-x769_(F-1000Mb)
See:
here
and
# SWH-FARMCORE:3/13-238-x836_(F-1000Mb-Trunk)<->SWH-FARMCORE2:1/1-3-x769_(F-1000Mb)
see:
here.
Note that this is after my change where I only log for the 5 sec plots,
data in wich discards were seen.
I do not know the significance of this now...but did want to pass it on to you. Connie.
Also see the Sorted
Discards for the Farm Switches.
Gary Buhrmaster reported on 12/13/02 at 7:38pm: Since around 1800 I have been attempting to change some parameters regarding the CEF tables inside the router due to some interesting events logged in the trace tables. The changes do not seem to have hurt anything, and may end up decreasing some of the lost packet issues (or at least spreading it out over a longer time period) but then again, maybe not (after almost any change, including sometimes just looking at certain entries, one must wait for 2-24 hours for things to restabilize to a new unknown state). I am pretty sure things are not any worse (but I could be wrong there too). We will keep monitoring the information we have, and it will be interesting to know if any of the monitoring that the systems group is doing sees any changes in behavior (good or bad).
This happened after the tests from testmove1 to farmboss2 and before the other ping tests described above. So I repeated the test from testmove1 to farmboss2 for 6000 12 byte pings separated by 1 second. This time there appeared to be no packet loss in 6000 packets. Based on previous results we should have seen about 360 packets lost or about 20 bursts.
Later Bill Weeks sent email on 12/15/2002 at 2:03am:
From our monitoring, it looks like the PINGFAIL messages stopped completely at 18:09 on Friday. They resumed again at 20:52 Saturday when the power glitched knocked down some machines including noma0257. At 00:46 this morning, when noma0257 was rebooted, the messages stopped again.
Congratulations, Gary, I think you have found and fixed the problem. --Bill
If the problem should occur again a next step would be to logon to the appropriate switches between testmove1 and farmboss2 and look for where the ping losses are occuring. I would start by looking at the 2 trunks between SWH-FARMCORE (10/15 & 9/15) and SWH-FARM1 (2/2 and 1/2), given the information earlier from Connie these are the most suspicious. Could it be anything to do with the channelizing, maybe try with only one trunk (the loads look like ~ 200 Mbits/s so we might get away with this for a bit). The strange losses of every other packet might have something to do with one trunk in the channel being bad, however the fact that Connie reports both trunks see losses may mean otherwise.