PingER Calibration and Context
Created: April 3, 1999;
Les Cottrell and
Warren Matthews.
Last updated on
May 22, 1999
Page Contents
Introduction
A
Round-trip Delay Metric for IPPM specifies that the calibration
and context in which
round trip metrics are measured SHOULD always be reported.
There are four items to consider:
the Type-P of test packets, the threshold of infinite delay (if any),
error calculation
and the path traversed by the test packets.
Type-P
The packet type is ICMP echo request and reply (see
RFC 792).
Loss threshold
The ping client times out after 20 seconds and considers responses
delayed by greater than
this to
have been lost.
We believe this is a reasonable setting since even for the hosts
with the slowest
response times (typically those in Russia when measured from elsewhere)
the number of ping
responses received after 20 seconds but under 100 seconds is less than 0.1%.
Calibration Results
Errors due to clock in the source host
The resolution of the ping clock is 1 msec.
Errors due to the difference in "wire time"
and "host time"
The way ICMP echo/ping measures the round trip time is for the ping
client in the host to read the
time from the system clock and place it in the packet to be sent. Then when the
packet is received back, the client compares the time in the packet
to the current system time to
provide the ping Round Trip Time (RTT).
This RTT is necessarily different from the round trip time as measured on the
wire and thus a systematic error is introduced by using the time reported by
ping.
To estimate the magnitude of the error introduced, we pinged from one host
(minos.slac.stanford.edu) to another host
(hermes.slac.stanford.edu)
on the same subnet and compared the RTTs reported
by a sniffer on the wire with those reported by ping.
Minos is an IBM RS/6000 250/80 running AIX 4.1.5,
and Hermes is a Sun Sparc 5/70 running SunOS 4.1.3.1. Minos is the host from where
we normally run the PingER monitoring code at SLAC. The resolution reported by
the sniffer and ping is 1 msec.
The results of the measurements for about 1500 pings are shown
in the figures below.
The first figure shows a histogram of the frequency of the wire RTTs. The line is a fit to
a power series with the parameters shown and a correlation coefficient
(R2) as
shown. The second figure shows a similar distribution for the RTT as reported by the
ping process running on Minos. In both cases the averages, standard deviations, medians
and the time range into which 95% of the meaurements fall are also shown.
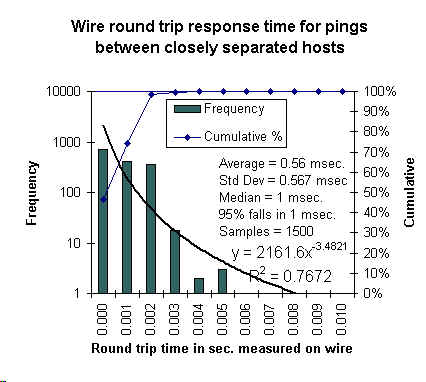
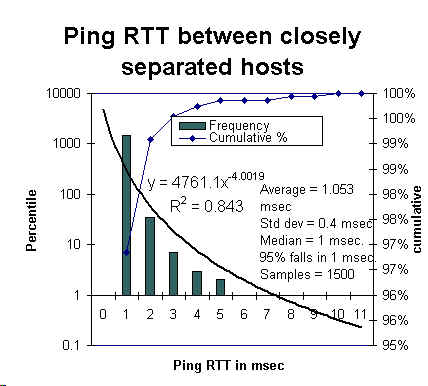
It can be seen that there is a difference of about 1 msec (1.053-0.56) in the averages, the
medians are the same, and the time range that includes 95%
of the measurements is 1 msec in
both cases. The two distributions are also seen to have similar standard deviations (0.56 and 0.4
msec.).
We thus report the 'wire time' versus 'host time' systematic error as 1 msec.
and the calibration error as 1 msec. for this pair of hosts.
We also made a test of 12,000 pings between the SLAC PingER monitoring
host (minos.slac.stanford.edu) and a host at LBNL (hershey.es.net). In this case
the difference between the RTT measured on the wire and that reported by ping was
always < 2 msec. and there were pings with RTTs of > 100 msec.
Thus at least in this sample, the long RTTs were
not related to monitoring host delays.
High statistics ping behavior
The ping distribution for a more extensive
(500K samples) measurement
between the same two hosts, minos and hershey, is seen below starting at
9:01am on April 23, 1999 and ending at 3:59am on April 29 1999. The pings were
separated by 1 second and the timeout was 20 seconds.
It can be seen that there is a narrow (IQR =
1msec.) peak at 4 msec. with a very long tail extending out to beyond 750 msec.
The black line is a fit to a power series with the parameters shown.
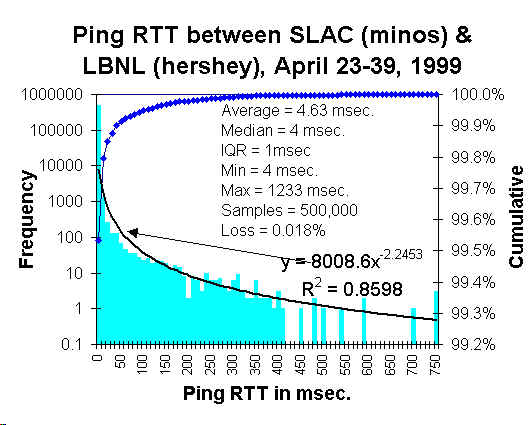
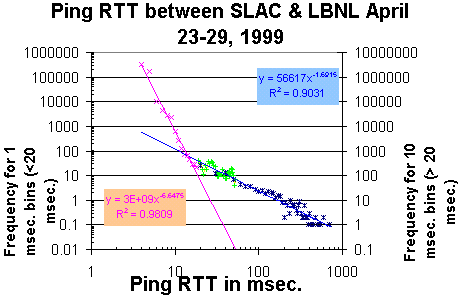
If one plots this data on a log-log plot (see below) then it can be seen that
there are two time scales (4-18 msec. and 18-1000 msec.) with quite different
behaviors. The bulk of the data (99.8%) falls in the 4-18 msec. region.
In the 4-18 msec. region (the magenta points) the data falls of as
y ~ A * RTT-6.6 whereas beyond 18msec. (the blue points)
it falls off as
y ~ B * RTT-1.7. The parameters of the fits are shown in the
chart. Note that in the 4-18 msec. region the data are histogrammed in 1 msec.
bins, whereas beyond that they are histogrammed in 10 msec. bins.
and the 2 y scales are adjusted
appropriately (the one for the wider bins beyond 18 msec. is a factor 10 greater
than the other). The green points are not used in the fits and are the
data histogrammed in 1 msec. bins for the range 19 msec. to 55 msec.
The behavior in the region 4 - 18 msec.
is that exhibited
by very chaotic processes such as fully developed turbulence or the
stock market, whereas the data beyond 18 msec.
is more characteristic of heavy-tailed or
long range similarity behavior.
If one looks at the RTT of just the pings in the 20-1000 msec. region as
a function of time of day, then one
gets the chart shown below:
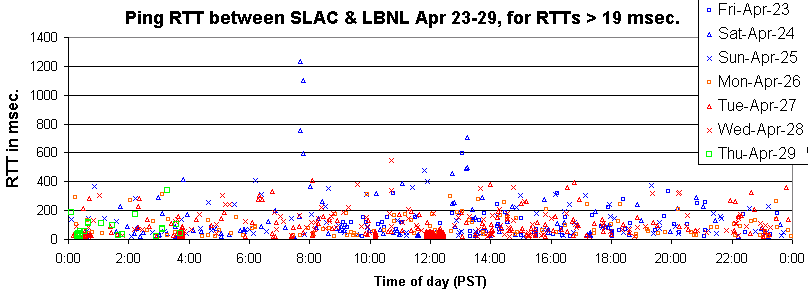
It can be seen that there are some long individual ping response times (up to 1200
msec. on the Saturday), as well as periods when there were a lot of pings with RTTs over 20 msec.
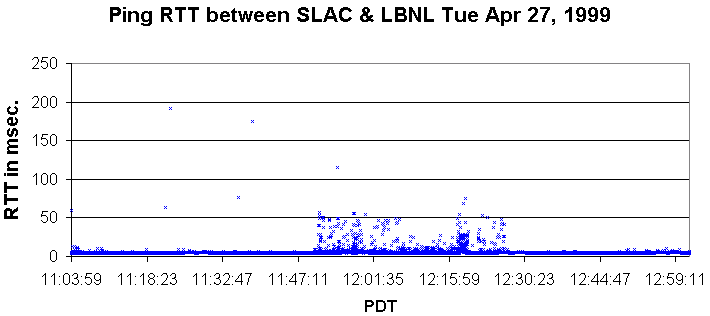
see for example Tuesday April 27 around noon. More details on the RTTs of these
latter pings can be seen below (there were no packet losses in the period shown in
the chart). It can be seen that for about 11:50 am thru 12:25pm there was a period of
increased RTT.
The pathchar
behavior between a host on the same subnet as minos (minos is an AIX host
and pathchar does not run on it) and hershey
is shown below:
>pathchar -q 64 hershey.es.net
pathchar to hershey.es.net (198.128.1.11)
mtu limitted to 8192 bytes at local host
doing 64 probes at each of 64 to 8192 by 260
0 FLORA03.SLAC.Stanford.EDU (134.79.16.55)
| 77 Mb/s, 462 us (1.77 ms)
1 RTR-CGB5.SLAC.Stanford.EDU (134.79.19.3)
| 294 Mb/s, 218 us (2.43 ms)
2 RTR-CGB6.SLAC.Stanford.EDU (134.79.135.6)
| 18 Mb/s, 276 us (6.53 ms)
3 RTR-DMZ.SLAC.Stanford.EDU (134.79.111.4)
| ?? b/s, -85 us (2.44 ms)
4 ESNET-A-GATEWAY.SLAC.Stanford.EDU (192.68.191.18)
-> 192.68.191.18 (1)
| ?? b/s, 1.42 ms (5.13 ms)
5?lbl1-atms.es.net (134.55.24.11)
| 245 Mb/s, 71 us (5.54 ms)
6 esnet-lbl.es.net (134.55.23.66)
| 9.7 Mb/s, 95 us (12.5 ms)
7 hershey.es.net (198.128.1.11)
7 hops, rtt 4.91 ms (12.5 ms), bottleneck 9.7 Mb/s, pipe 42418 bytes
Other sanity checks
Ideally such a wire
measurement should be made for each monitor-remote host pair. This is usually
not practical, so a possibility is for each monitoring host to
ping itself on a regular basis as a sanity check. However as described below
this is usually of limited value.
One might assume that self pinging would
give an overestimate of the RTT overhead caused by
the monitoring host (since in the self ping case:
the host has to create and send the echo
request; receive the echo request process it and echo the response;
and receive it back again
and process the response - whereas in the non-self ping case the monitoring
host does not have to handle receiving the request processing it and sending
the response). However, when a host self pings itself, the packets do
not usually go onto the physical network. As a result the client does not
usually
have to do an I/O wait to get the response back. Typically one
would expect self ping times to be of the order
of 0-3 msec. For example
in the case of the SLAC PingER monitoring host (minos)
the probability of the self-ping RTT being >= 1 msec is < 0.1%.
In the non-self ping case the client will probably
have to do an I/O wait to read the response back. If the client system is busy, then
there can be considerable delay before the client task is dispatched again.
This
may occasionally lead to much longer
RTT times being recorded by ping than are seen on the wire. For example,
10,000 pings to hershey.lbl.gov from minos.slac.stanford.edu on
4/5/1999 gave an Inter Quartile Range (IQR) of
1 msec (2 msec.), a median of 4 msec (5 msec.), that fell off
exponetially between 4 msec & 25
msec with an R2 of 0.93 (or in other words a good fit),
but had 13 (15) RTTs > 30 msec with a fairly flat
distribution from 40 to 360 msec.(the numbers in parentheses in this sentence
are for the reverse direction). For both these hosts (minos and hershey) the
self-pings had a probability of < 0.1% of being > 1 msec. The large RTTs
of these few outliers suggests that using the maxima, or any statistic that is
sensitive to large outliers is not a good idea.
Thus an alternative is
for the host to monitor a second host at the same site in order to get
a more realistic idea of the impact of the host on the RTT (this assumes
that a response time of a few msec. will be sufficient to cause the
ping client to do an I/O wait). When we do this
between minos and ns2 (a Sun Sparc 5/70 running SunOS 4.1.3.1),
two hosts on the SLAC LAN separated by one router hop,
we get a median RTT of 3 msec., an IQR of 1 msec. and a probability of
< 0.01% for an RTT of > 10 msec.
Providing an estimate of the error
introduced by the remote host requires using a sniffer to measure
and compare the wire times of the incoming echo request time with the
outgoing echo response time. This is expected to be small (<
1 msec. - for example, on a 166MHz Intel Pentium running
Windows 98 it is about 350 usec.) since the echo
response is usually done in the kernel and should not require
an I/O wait to turn-around the packet.
If one is measuring Internet traffic, usually
the turn-around time of the remote host will be small compared to the complete
ping RTT so it may only be necessary to ensure that this is so, i.e.. ensure the
turn-around time is < 1-2 msec, when one is measuring response time of 50 msec.
or greater (assuming a systematic error contribution from the
monitoring host of < 4% is acceptable).
Error introduced into "jitter" measurements
One way to measure jitter is to assume the pings are sent out at regular
intervals (i.e. 1 second by default) and then measure variation in the
separation of the ping responses.
We can measure the accuracy of this assumption
by measuring the distribution of the actual wire
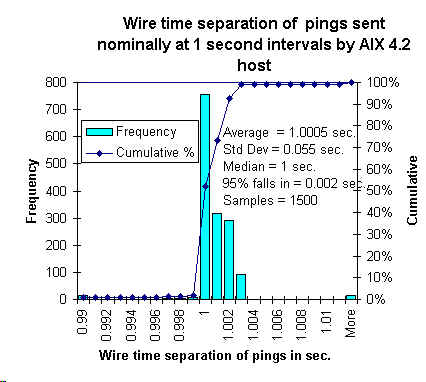
times between the pings. The figure below shows this for the host used at
SLAC for the ping monitoring. The IQR of this distribution is 1 msec, and 95%
of the pings are sent at 1 second intervals to within an accuracy
of 2 msecs.
As another check on the ping intervals we ran pings from
a Linux host (doris.slac.stanford.edu running Red Hat 5.2) to a Windows NT
(atreides.slac.stanford.edu running Windows NT 4/SP4) at 07:13:14 on 5/21/99, and ran 65,000
pings. Both hosts were on the same subnet.
Now 65,000 seconds=18 hours, 3 mins and 20 seconds, so the pinging
should've finished at 01:16:34, and that is exactly the date stamped on
the end of the file.
Path
We use traceroute to determine the paths. To assist with this we recommend
installing reverse traceroute servers
at the monitoring and other strategic sites. It is also important to keep
a history of routes used to help understand changes in performance seen
in historical reports. We are planning to use
traceping to gather, store, analyze
and make this historical information available.
[ Feedback ]