
Principal Investigator (University Collaborators): |
Harvey B. Newman, California
Institute of Technology |
Principal Investigator (DoE Laboratory Collaborators) |
Richard P. Mount, Stanford Linear
Accelerator Center |
Collaborators:
California Institute of Technology |
Harvey B. Newman,
Julian J. Bunn, James C.T. Pool, Roy Williams |
Argonne National Laboratory |
Ian Foster,
Steven Tuecke |
Berkeley Laboratory |
Stewart C. Loken,
Ian Hinchcliffe |
Brookhaven National Laboratory |
Bruce Gibbard, Michael
Bardash, Torre Wenaus |
Fermi National Laboratory |
Victoria White,
Philip Demar, Donald Petravick |
San Diego Supercomputer Center |
Margaret Simmons, Reagan Moore, |
Stanford Linear Accelerator Center |
Richard P.
Mount, Les Cottrell, Andrew Hanushevsky, David Millsom |
Thomas Jefferson National Accelerator Facility |
Chip Watson, Ian Bird |
University of Wisconsin |
Miron Livny |
The
Particle Physics Data Grid
Abstract
The Particle Physics Data Grid has two objectives: delivery of an infrastructure for widely distributed analysis of particle physics data at multi-petabyte scales by thousands of physicists, and acceleration of the development of network and middleware infrastructure aimed broadly at data-intensive collaborative science.
The specific research proposed herein will design, develop, and deploy a network and middleware infrastructure capable of supporting data analysis and data flow patterns common to the many particle physics experiments represented among the proposers. Application-specific software will be adapted to operate in this wide-area environment and to exploit this infrastructure. The result of these collaborative efforts will be the instantiation and delivery of an operating infrastructure for distributed data analysis by participating physics experiments. The components of this architecture will be designed from the outset for applicability to any discipline involving large-scale distributed data.
Among the hypotheses to be tested are these:
- that an infrastructure built upon emerging network and middleware technologies can meet the functional and performance requirements of wide area particle physics data analysis;
- that specific data flow patterns, including sustained bulk data transfer and distributed data access by large numbers of analysis clients, can be supported concurrently by common middleware technologies exploiting emerging network technologies and network services;
- that an infrastructure based upon these emerging technologies can be compatible with commercial middleware technologies such as object databases, object request brokers, and common object services.
The proposed collaboration unites leaders in particle physics computing and in middleware and network research.
The
Particle Physics Data Grid
Contents
1 Executive Summary.................................................................................................................................................
4
2 Background and
Motivation.................................................................................................................................
5
2.1 The Particle
Physics Data Problem..............................................................................................................
5
2.2 Why this is an
NGI Problem..........................................................................................................................
5
2.3 Relevance to the
Generic Needs of Large-Scale Science..........................................................................
6
2.4 Leverage of
Particle-Physics and CS Resources – A Unique Opportunity........................................... 6
2.5 Long-Term Vision...........................................................................................................................................
6
3 Preliminary Studies..................................................................................................................................................
7
3.1 ANL: Globus Grid
Middleware Services.....................................................................................................
7
3.2 SLAC: The
Objectivity Open File System (OOFS)....................................................................................
7
3.3 Caltech: The
Globally Interconnected Object Databases (GIOD) project.............................................. 8
3.4 FNAL: A Data
Access framework (SAM)..................................................................................................
8
3.5 LBNL: The
Storage Access Coordination System (STACS)...................................................................
9
3.6 ANL: Scalable
Object Storage and Access................................................................................................
9
3.7 U. Wisconsin:
Condor Distributed Resource Management System....................................................
10
3.8
SDSC:
The Storage Resource Broker (SRB).............................................................................................
10
3.9 China Clipper
Project....................................................................................................................................
11
4 Technical Approach.............................................................................................................................................
11
4.1 FY 1999 Program
of Work............................................................................................................................
11
4.1.1 High-Speed
Site-to-Site File Replication Service............................................................................
12
4.1.2 Multi-Site
Cached File Access..........................................................................................................
13
4.1.3 Middleware
Components Required for First-Year Program of Work...........................................
14
4.1.4 Data
Center Resources Relevant to FY 1999 Program of Work....................................................
16
4.1.5 Network
Resources Relevant to FY 1999 Program of Work..........................................................
16
4.1.6 FY
1999 Work Breakdown by Site (FTE)..........................................................................................
17
4.1.7 First
Year Milestones..........................................................................................................................
17
4.2 FY 2000 –
FY 2001 Program of Work.........................................................................................................
18
4.2.1 Outline
FY 2000 – FY 2001 Work Breakdown by Site (FTE total for the two years)................. 19
5 Linkages and
Technology Transfer...................................................................................................................
20
6 Management Plan..................................................................................................................................................
20
7 Bibliography...........................................................................................................................................................
22
The
Particle Physics Data Grid
For decades, particle physics has been the prime example of science requiring that hundreds of distributed researchers analyze unwieldy volumes of data. As we move into the next millennium, the rapid rise of data volumes in many sciences will be further accelerated by the IT2/SSI initiative. We expect work on distributed data management for particle physics to broaden rapidly to face the more general challenge of networked data management for data-intensive science.
We intend to exploit the enthusiasm of particle physicists for a revolution in distributed data access to drive progress in the necessary middleware, networks and fundamental computer science. Our strategy is to engage the user community from the first year through the rapid creation of the Particle Physics Data Grid. This rapid progress will only be possible because many candidate middleware components already exist, because the collaborators have access to ESnet and to high-performance research networks, and because the collaborators can leverage the data centers at the particle physics laboratories. Even though we plan a first year focused on integration of existing middleware, we expect this work to generate a deepening understanding of the middleware and computer science needs and opportunities. Work on addressing these needs will begin in the first year and will intensify in the subsequent years of the project.
The first-year work will implement and run two services in support of major particle physics experiments. The “High-Speed Site-to-Site File Replication Service” will use a bulk-transfer class of network service to achieve data replication at 100 megabytes/s. The “Multi-Site Cached File Access” service will deploy file-cataloging, cache-management and data movement middleware to move data transparently to the particle physics data center most accessible to each user. Particle physics is increasingly presenting data to physicists in terms of inter-related objects rather than files. However, practical implementations of object database systems store and access data in the form of large files that will be handled efficiently by the Data Grid.
These implementation of these services will be achieved by the integration of existing middleware components developed previously by the proposers, including security and data transfer services provided by the ANL Grid middleware toolkit, the LBNL Storage Access Coordination System and Distributed Parallel Storage System, the SDSC Storage Resource Broker, the U. Wisconsin MatchMaker system, the SLAC Objectivity Open File System, and elements of Caltech's Globally Interconnected Object Databases. These components will be combined with advanced network services to produce the Particle Physics Data Grid software system. This system will then be applied to real physics data by the proposing institutions, enabling realistic evaluation of both the integrated system and the underlying network services.
The Particle Physics Data Grid is a NGI problem because of the sophistication of the network services and middleware required. The sophistication is necessitated by a data management problem with almost unlimited goals: today’s ideal data analysis environment would allow researchers all over the US to query or partially retrieve hundreds of terabytes within seconds. Within ten years queries will be aimed at hundreds of petabytes. Raw network bandwidth alone is not a sufficient or efficient solution. The network must become intelligent, logically incorporating and managing data caching resources at its nodes, and exploiting appropriate classes of service for control functions and bulk data transfers at differing priorities.
The proposed research will be undertaken by a talented project team with extensive prior experience in high energy physics data management (ANL, BNL, Caltech, FNAL, JLAB, LBNL, SLAC), distributed data management (LBNL, SDSC), high-performance network middleware (ANL, LBNL, Wisconsin), and high-performance networking (ANL, LBNL). Subsets of the team have worked together closely over the years on such projects as the HENP grand challenge (ANL, BNL, LBNL), NSF "National Technology Grid" (ANL, U. Wisconsin, SDSC) ,DOE2000 (ANL, LBNL), and Clipper (ANL, LBNL, SLAC). It is this combination of expertise and history of joint work that makes us believe that the ambitious goals of this project are possible for the relatively modest proposed budget.
Particle physics is the study of the elementary constituents of matter under conditions typical of the first microsecond of our universe. The particle world is a quantum world in which only probabilities, not precise outcomes, may be predicted. To measure the physics of particles, petabytes of data describing vast numbers of particle interactions must be measured using “detectors” weighing thousands of tons and composed of hundreds of thousands of measuring devices.
The scale of particle accelerators, detectors and data analysis requires large collaborative efforts. International collaborations of hundreds of physicists have been the norm for nearly two decades. The LHC experiments now under construction will start to take data in 2005 and have required the formation of intercontinental collaborations involving thousands of physicists. Although accelerators are usually constructed by laboratories, universities play a large role in detector construction and provide the intellectual power essential for data analysis. Networks and tools supporting collaborative analysis of vast datasets are vital for the future of particle physics. In particular, the limitations of wide-area data management restrict the both the precision and the discovery potential of experiments.
These limitations are not new. Particle physicists have a history of actively promoting wide-area networking as an essential tool and have often had to reduce the scope of detector hardware to pay for networking vital for its exploitation.
Particle physics data presents a unique combination of high data volume and high complexity. Thirty years ago raw particle physics data was images on photographic film. The volume of data comprised in a hundred thousand high-resolution images was intractable, so features (particle tracks and vertices) were extracted from the images and could then be analyzed using computers. This approach of handling only features (or features of features) has remained necessary as detectors became electronic rather than photographic and produced ever greater data volumes. This logical compression of data makes the total volume tractable at the expense of a very complex structure.
The precision and discovery potential of particle physics will be enhanced as we move closer to today’s impossible dream: that researchers at universities all over the US could query and partially retrieve hundreds of terabytes within seconds. The scale is set to rise from hundreds of terabytes to hundreds of petabytes over the next decade. These goals cannot be met by bandwidth alone. They require the more intelligent approach to the creation of intelligent networks that is the core of NGI. Particle physics hopes to drive stimulate and take advantage of NGI in three areas:
1. Differentiated services [ZJN97] will allow particle-physics bulk data transport to coexist with other network traffic. Bulk data transfer may use relatively high latency services; in some cases services such as scheduled overnight transfers are relevant. High latency is especially tolerable for anticipatory bulk transfers, loading remote caches with data likely to be accessed in the future.
2. Distributed caching technology [MBMRW99, TJH94] will be vital. Particle-physics data analysis relies on the highly non-uniform probability that each data element within petabytes will be required during data analysis. As in many sciences, a few percent of the data are ‘hot’ at any one time and distributed caching technology will be able to achieve revolutionary improvements in data analysis speeds.
3. Robustness of the distributed service [Bir97] is a key requirement for particle physics and any collaborative science needing a complex distributed ensemble of network and data caching resources. Complex systems built from today’s working components must be expected to be close to unusable until major efforts have been made to achieve robustness at the architectural and component levels.
Collaborative access to large data volumes will become a requirement for progress in many sciences, and especially the Global Systems and Combustion thrusts of SSI. At first sight, these sciences have a data management and visualization problem that is based on 3-D grids and images and is thus very different from that of particle physics. However, the bandwidth of the human eye is limited, and direct visualization of the expected multi-petabyte datasets will be of limited value compared with the ability to explore more compact but also more complex datasets containing extracted features. We expect a convergence of the data-management needs of particle physics and many other sciences over the next decade.
There are good reasons to regard particle physics as a pioneer in a world that will become increasingly preoccupied with wide-area data management. The march of information technology is increasing computing power slightly faster than storage capacities and much faster than storage bandwidths. Wide area network bandwidths are set to surpass those of storage devices. Thus wide-area data management will become a principal focus of future applications of information technology.
This project is ambitious. It requires a large-scale collaboration between universities and laboratories and between particle physicists and computer scientists. The project depends crucially on the exploitation and leverage of the networks, data storage systems, middleware and applications code that have already been developed by or are available to the proposers. It will also benefit from the impossible-to-simulate community of demanding particle-physics users.
The NGI-funded effort will result in major progress in data management for particle physics and in widely applicable middleware for future of networking in support of data-intensive science. The project will act as a catalyst to create an effective collaboration between Computer Scientists and Particle Physicists. The collaborators are motivated by this unique opportunity to set up a true partnership between a most demanding scientific application and Computer Science.
We intend that the Particle Physics Data Grid is one of the projects that will be coordinated into a longer-term plan, incorporating as a minimum both NSF IT2 and DoE SSI efforts on distributed data management for data-intensive science. In this long-term vision it is appropriate to plan three major phases for the Data Grid:
1. Support for distributed transparent read and write access to high volume data;
2. Support for ‘agent technology’ where data-intensive tasks move automatically to the node in the Grid at which they can be most effectively executed;
3. Support for agent technology and ‘virtual data’. Virtual data are derived data defined only in terms of the input data and the process or agent that could create the derived data. Whether a virtual data object or file exists in many, one or zero copies is left to the Data Grid to decide. If it exists in zero copies, a copy must be created by the Grid if the virtual object or file is accessed.
Substantial progress towards this vision will require major advances in network-aware middleware, in distributed and scalable metadata catalogs and in the integration of scalable software configuration management into Grid services.
The collaborators in this proposal bring a vast pool of experience and as well as existing software and systems that are directly relevant to this proposed project. Without this base to build on, it would be impossible to achieve the goals stated, especially in the first year. We summarize below the work done and systems developed in the participating institutions, and their relevance to this project.
The Argonne/ISI Globus project has developed a range of basic services designed to support efficient and effective computation in Grid environments [FK98,FK99b]. These services have been deployed in a large multi-institutional testbed that spans some 40 sites worldwide and has been used in numerous application projects ranging from collaborative design to distributed supercomputing. Services relevant to the current project include:
Ę The Grid Security Infrastructure (GSI) [FKTT98], which provides public key-based single sign-on, run anywhere capabilities for multi-site environments, supporting proxy credentials, interoperability with local security mechanisms, local control over access, and delegation. A wide range of GSI-based applications have been developed, ranging from ssh and ftp to MPI, Condor, and the SDSC Storage Resource Broker.
Ę The Metacomputing Directory Service (MDS) [FFKL+97], which provides a uniform representation of, and access to, information about the structure and state of Grid resources, including computers, networks, and software. Associated discovery mechanisms support the automatic determination of this information.
Ę Globus resource management services [CFNK+98,CFK99,FKL+99,HJFR98], which provide uniform resource allocation, object creation, computation management, and co-allocation mechanisms for diverse resource types.
Ę The Global Access to Secondary Storage (GASS) service [BFKTT99], which provides a uniform name space (via URLs) and access mechanisms for files accessed via different protocols and stored in diverse storage system types (HTTP, FTP are currently supported; HPSS, DPSS are under development.
The Objectivity Open File System (OOFS) [HN99] interface is a joint development effort between Stanford Linear Accelerator Center (SLAC) and Objectivity, Inc. The interface provides a standard external interface between an Objectivity database and a storage system, be it a Unix file system or a Mass Storage System such as the High Performance Storage System, HPSS. The OOFS was designed with secure data distribution and high latency storage media (e.g., tape or wide-area networked storage) in mind. The protocols provide the means to optimize data access in a distributed environment while maintaining the highest possible throughput. Thus, the interface is an ideal platform for distributed cache management systems such as the Globus tool-kit and the Storage Request Broker (SRB). Thus far, the OOFS has been interfaced with HPSS in a local-area distributed environment and has shown that the design points were well chosen for this environment. Given that Objectivity/DB may become a standard database system for many particle physics experiments, the OOFS along with Objectivity applications not only provide an excellent test-bed but the opportunity for significant advances in particle physics data analysis.
The GIOD project, a joint effort between Caltech, CERN and Hewlett Packard Corporation, has been investigating the use of WAN-distributed Object Database and Mass Storage systems for use in the next generation of particle physics experiments. In the Project, we have been building a prototype system in order to test, validate and develop the strategies and mechanisms that will make construction of these massive distributed systems possible.
We have adopted several key technologies that seem likely to play significant roles in the LHC computing systems: OO software (C++ and Java), commercial OO database management systems (ODBMS) (Objectivity/DB), hierarchical storage management systems (HPSS) and fast networks (ATM LAN and OC12 regional links). We are building a large (~1 terabyte) Object database containing ~1,000,000 fully simulated LHC events, and using this database in all our tests. We have investigated scalability and clustering issues in order to understand the performance of the database for physics analysis. These tests included making replicas of portions of the database, by moving objects in the WAN, executing analysis and reconstruction tasks on servers that are remote from the database, and exploring schemes for speeding up the selection of small sub-samples of events. The tests touch on the challenging problem of deploying a multi-petabyte object database for physics analysis.
So far, the results have been most promising. For example, we have demonstrated excellent scalability of the ODBMS for up to 250 simultaneous clients, and reliable replication of objects across transatlantic links from CERN to Caltech. In addition, we have developed portable physics analysis tools that operate with the database, such as a Java3D event viewer. Such tools are powerful indicators that the planned systems can be made to work.
Future GIOD work includes deployment and tests of terabyte-scale databases at a few US universities and laboratories participating in the LHC program. In addition to providing a source of simulated events for evaluation of the design and discovery potential of the CMS experiment, the distributed system of object databases will be used to explore and develop effective strategies for distributed data access and analysis at the LHC. These tests are foreseen to use local, regional (CalREN-2) and the I2 backbones nationally, to explore how the distributed system will work, and which strategies are most effective.
The SAM (Sequential Access Method) project at Fermilab [B+98] [LW+98] will provide a data access framework for Run II experiments, in particular the D0 experiment. Since the total data for one experiment is expected to exceed one petabyte there is a need to provide a data management framework and client data access software in order to control and coordinate access to the data and to perform intelligent distributed caching of data [L+97].
The data access framework provides the services by which data is written, cataloged, and read. Data discovery services resolve logical definitions of data, and queries on data, into physical files, or in some cases specific events within files. Station services implement management and control of a Station (a particular grouping of physical resources) including access control based on particular physics group and type of data access. Project services carry out delivery of data and cache management for one particular dataset or collection of data (a Project) which may then be accessed by one or several clients, in either a coordinated or unassociated fashion. Global Resource Management services re-order and regulate file staging requests, while a further level of management of staging requests is done by the underlying Enstore Storage Management system [B+99]. This regulation and ordering is based on optimization of file retrieval from tape storage, experiment and physics group policies, ‘usage’ metrics for Robot and Mass Storage System, and on coordination with CPU resources controlled via the LSF batch system .
The SAM system is implemented as a set of distributed servers, with clearly defined interfaces. There is a well-defined file level interface to a Storage Management System – currently the Enstore system developed at Fermilab, which uses the pnfs file meta-data catalog from DESY [P+98]. Components of SAM include Station Masters (responsible for a logical grouping of resources), Project Masters (responsible for delivery of a particular subset of data to one or more clients), Cache Managers and File Stagers, System Logger and Information Server and a Global Resource Manager. All meta-data about the files and events in the system is provided via a SAM database server component, which currently stores and retrieves data from an Oracle relational database . There is an ongoing research effort with Oracle to use features of Oracle 8 to provide efficient index capabilities for individual event trigger bits and other event level attributes; a catalog of more than 2 billion events is planned for [VW+98].
Since the system is modular and distributed, with all components and clients intercommunicating via CORBA/IDL interfaces, it is an ideal testbed for incorporating and integrating several of the other components and services forming part of this proposal. Since it is also still under development, with a target final system deployment of March 2000, it also provides an opportunity to either enhance or replace a needed component, using existing components developed by collaborators on this proposal. Early versions of the entire framework are already in use and will be used for work with simulated data through commissioning of the detector. Some of the most challenging work remaining is that involving Global Resource Management and use of the data access framework across a WAN.
LBNL has for a long time been involved in developing data management technology for scientific applications. More recently, several projects have focused on research and development for scientific applications that generate very large quantities of data. The volumes of data may reach hundreds of terabytes per year that need to be stored on robotic tape systems. In particular, the OPTIMASS project [CDLK+95a, CDLK+95b] developed the technology to reorganize and access spatio-temporal data from robotic tape systems. Another project, called the HENP-Grand Challenge [BNRS98, SBNRS98, SBNRS99], developed the technology and software to manage terabytes of High-Energy and Nuclear Physics data and their movement to a shared disk cache. This system, called STACS (Storage Access Coordination System) [STACS99] was integrated into the production analysis system for the STAR and PHENIX experiments at BNL.
STACS [http://gizmo.lbl.gov/sm] is directly relevant to this proposed project. It has three main components that represent its three functions: 1) The Query Estimator (QE) uses the index to determine what files and what chunks in each file (called “events” in physics applications) are needed to satisfy a given range query. 2) The Query Monitor (QM) keeps track of what queries are executing at any time, what files are cached on behalf of each query, what files are not in use but are still in cache, and what files still need to be cached. 3) The Cache Manager is responsible for interfacing to the mass storage system (HPSS) to perform all the actions of staging files to and purging files from the disk cache. The QE was designed for particle physics data and can be readily used for this project. The QM will only be used in a local system, as the Globus, Condor, and SRB services can be used to manage the distributed resource management. The CM will be used to manage the transfer of data from HPSS to a local cache, and will be extended to use services to move data between distributed caches.
Argonne is a leader in research and development of scalable technologies for particle physics data storage and access. Argonne has developed a persistent object store compliant with a substantial subset of the Object Database Management Group's ODMG-2.0 standard. The storage layer has been implemented on multilevel and distributed file systems and on parallel I/O systems, including Vesta and PIOFS. Argonne has also provided an implementation of the Object Management Group's Persistent Object Services Specification, one of the higher-level Common Object Services defined by the CORBA community.
Argonne is a partner in the HENP Grand Challenge project (for details, see the LBNL STACS text below), contributing significantly to the overall architectural design, and taking responsibility in particular for client-side components. These include an Order-Optimized Iterator (the primary means by which clients receive data), a gcaResources facility (the client code connection to the STACS environment and middleware services), connections to application-specific storage services (e.g., transaction management for database implementations) via a localDBResources service, and, jointly with Brookhaven, the code to connect the Grand Challenge architecture to application-specific data. Argonne has also provided parallel execution capabilities to Grand Challenge clients, performed parallel scalability tests and analyses for commercial object databases, and implemented Grand Challenge-like services for non-Grand Challenge applications using such databases, supporting, for example, query estimation and order-optimized iteration over Objectivity databases, without the STAC prefetching services, within the constraints of the database's native predicate query capabilities.
Argonne has been nominated to lead the US software effort for the ATLAS experiment at CERN, and will play a key role in the adoption and integration of emerging network and middleware technologies into a collaborative LHC computing environment.
Conventional resource management
systems use a system model to describe resources and a centralized scheduler to control
their allocation. We argue that this paradigm
does not adapt well to distributed systems, particularly those built to support
high-throughput computing [LR99]. Obstacles include heterogeneity of resources, which make
uniform allocation algorithms difficult to formulate, and distributed ownership, leading
to widely varying allocation policies. Faced
with these problems, we developed and implemented the classified advertisement (ClassAd)
language and a matchmaking framework, a flexible and general approach to resource
management in distributed environments with decentralized ownership of resources [RLS98].
Novel aspects of the framework include a semi-structured data model that combines schema,
data, and query in a simple but powerful specification language, and a clean separation of
the matching and claiming phases of resource allocation. The representation and protocols
result in a robust, scalable and flexible framework that can evolve with changing
resources and policies. The framework was
designed to solve real problems en-countered in the deployment of Condor, a high
throughput computing system developed at the University of Wisconsin— Madison. Condor
is heavily used by scientists at numerous sites around the world [BL99]. It derives much of its robustness and efficiency
from the matchmaking architecture. We plan to
adapt the matchmaking framework for matching file requests to grid nodes that can provide
them, and using the Globus network performance information, to manage the transfer of
files in the system.
The SDSC Storage Resource Broker
(SRB) is client-server middleware that manages replication of a data collection across
multiple storage systems. The SRB provides a
uniform interface for connecting to file systems [BMRW98], databases, archival storage
systems, and Web sites. The SRB, in
conjunction with the Metadata Catalog (MCAT), supports location transparency by accessing
data sets and resources based on their attributes rather than their names or physical
locations [BFLM+96]. An information discovery
API is provided that allows applications to directly query the metadata catalogs and
retrieve data through one of several data handling APIs.
Data discovery and retrieval is driven by the metadata and requires little
or no user intervention. The SRB utilizes the
metadata catalog to determine the appropriate protocol to use to access the collection
storage systems. Client applications can
access and manipulate data set entities without having to know low level details, such as
location and format, about these entities. Alternatively,
the application may have already obtained the necessary metadata about the entity, in
which case it can call a "low level" API which allows direct access to the
entity without having to go to the catalogs for further information.
SRB can also be distributed. An SRB can act as a client to another SRB. This is the mechanism used to support inter-SRB
communications. Each SRB manages a set of
storage resources. It is also possible to
configure the system such that a storage resource is managed by more than one SRB. This provides support for fault-tolerance, in case
one of the controlling SRB's fails. Finally,
an SRB may or may not have direct access to the metadata catalogs. If an SRB does not have direct access to a
catalog, it can use the inter-SRB communication mechanism to contact one of the other
SRB's, which has access to the catalog. Distributed
SRB implementations may be needed due to: 1) Logistical and administrative reasons -
different storage systems may need to run on different hosts, thus making a distributed
environment a necessity; 2) improved performance - a single SRB may become a bottleneck in
a distributed system, and 3) improved reliability and availability - data may be
replicated in different storage systems on different hosts under control of different
SRB's [BMRS+98]. We plan to use a distributed
SRBs in this project.
The China Clipper Project is a joint project with ANL, LBNL, and SLAC which is focused on developing technologies required for widely distributed data-intensive applications, in particular particle-physics data analysis. Clipper leverages existing technologies such as the distributed parallel storage system DPSS, Globus, and ESnet and NTON (OC-12 networks) with the goal of achieving high-performance, guaranteed data-rate bulk transfers. In one set of initial experiments, data transfer rates of 57 megabyte/s were demonstrated over an OC-12 network between LBNL and SLAC for a particle-physics application. In this experiment, data was read in parallel from four servers at a transfer rate of 14.25 megabytes/sec per server and delivered into the remote application memory, ready for analysis algorithms to commence operation. In aggregate, this was equivalent to moving 4.5 terabytes/day. In other experiments, data rates of 320 megabit/s were demonstrated across an OC12 ESnet link between ANL and LBNL. This work has demonstrated the feasibility of the data transfer rates required for the work proposed here and has also provided valuable experience in the network instrumentation, optimization, and debugging required to achieve high sustained rates in wide area networks.
The Particle Physics Data Grid will provide a distributed data management system supporting access to multi-petabyte datasets. Although many particle physicists will be provided with an object-database front end, this will be supported through a more generic distributed file-management interface, optimized for the access to and transport of thousands of individual files each with a size of a few gigabytes. We believe that we are able to leverage existing middleware and existing data centers to create a petabyte-capable Data Grid within the first year, and that the feedback from this deployment will be vital to steer our middleware development in the subsequent years. Reflecting the importance we place on rapid progress in the first year, we describe the first year’s program of work and then outline the likely program in the second and third years.
The first-year focus will be on the deployment and integration of existing tools, data management hardware and networks. We believe that this focus will be extremely effective in generating insight into the computer science of networked data management. Neither the creators nor the potential users of middleware toolkits such as Condor, Globus, Grand-Challenge, MCAT, OOFS, SAM, SRB etc, can be totally sure how complete or compatible such tools will be as components of the planned interworking system. Thus the plan outlined below is only intended to be a starting point. We will put in place an agile technical management for this project so that the plans can be amended as experience is gained.
First-year efforts will be concentrated on providing distributed data access at the file level. This delivers a service that can be immediately useful to users from other disciplines than particle physics and from which other more specific services can be developed. Our users who need a distributed persistent object service will be able to use databases and middleware such as Objectivity DB plus OOFS to store persistent objects in containers that can be mapped on to a generic file system.
Two deliverable systems have been identified with the aim of motivating and focusing the first-year effort:
This service will be used between SLAC and LBNL to replicate data acquired by the BaBar experiment, and between Fermilab and several sites participating in the Run 2 physics program. The service will be used to transfer hundreds of terabytes per year and the target point-to-point throughput must be at least 100 megabytes/s to allow the replication service to catch up rapidly after interruptions. This throughput is intentionally chosen to be above that expected to be provided by ESnet during the first year, making it essential to exploit bulk data transport provided by NTON and MREN in addition to the more general services provided by ESnet.
Our work in this area will build on early experiences gained in the Clipper project but here must be extended to provide greatly improved reliability and to coordinate end-to-end movement from archive to archive. We are particularly interested in exploring the following issues:
Ę Use of differentiated services (diffserv) capabilities in two modes, both of which are important for future Data Grid applications: predictable (high-priority) delivery of high-bandwidth data streams and reliable background (lower-priority than other traffic) transfers. Considerable work is required to understand how protocols and diffserv capabilities are best configured for efficient operation in these two modes.
Ę The use of integrated instrumentation to detect and (ultimately) to diagnose and correct performance problems in long-lived high-data-rate transfers. Here, we hope to build on both the existing NetLogger system [TJC98] and on more sophisticated instrumentation capabilities proposed in two complementary DOE NGI Technology proposals: “Network Monitoring for Performance Analysis and for Enabling Network-Aware Applications” (LBNL, KU) and “A Uniform Instrumentation, Event, and Adaptation Framework for Network-Aware Middleware and Advanced Network Applications” (ANL, UIUC).
Ę The use of coordinated reservation and allocation techniques to achieve end-to-end performance guarantees across tape, disk, computers, and networks. Here we hope to build on capabilities provided by the Globus Architecture for Reservation and Allocation, which provides advance reservation and co-allocation capabilities [CFK99,FKL+99,HJFR98,LW+98] and to test out and extend this work in the context of the SAM data access framework and its Global Resource Manager component.
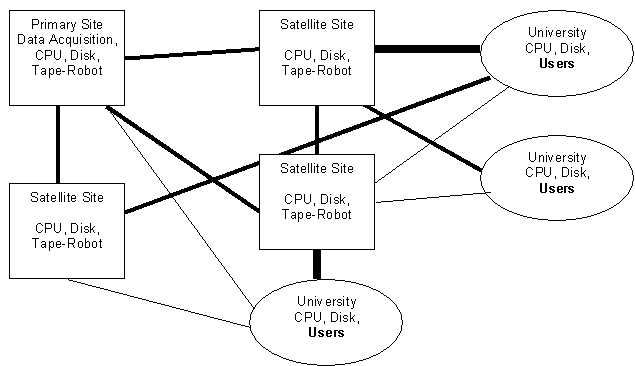
The first-year implementation will allow users to access files stored across several sites by location-independent name. The most readily accessible copy of a desired file will be located and may be copied to a disk cache at either or both of the university and a nearby satellite site. The data transfer itself can use the high-speed data transfer service described above; the focus of our work here will be on the middleware required to manage caching and access.
The physical components of the system are shown in the diagram. The purpose of the system is to serve users, predominantly at universities. The core services of the Data Grid are provided by well-connected computer centers, sited mainly at national laboratories. For any particular physics experiment, one site in the Data Grid will be the ‘Primary Site’, the original source of the data; sites may simultaneously act as primary and satellite sites when serving more than one user community.
The first-year implementation will be optimized for intelligently cached read access to files in the range 1-10 gigabytes from a total data set size of the order of 1 petabyte. In the first year deployment and use of the Data Grid will proceed in parallel with the development of QoS-aware middleware. We will integrate the existing versions and provide feedback to their continued development. In support of the applications we will deploy a distributed file catalog and provide for query description and resolution.
The applications will be instrumented to allow us to study the characteristics and profile the system under a wide range of user access patterns and loads. This will provide us with knowledge to successfully develop the fully operational system where the control and bulk data transfers must be differentiated to provide a robust, responsive system. We will use the deployed applications to study the implications of: local and distributed cache management; pre-caching, just-in-time delivery, and predictive caching; replication and mirroring of the files; query estimation techniques.
An additional first-year goal will be to achieve robustness in making files transparently available to the end users at multiple sites. In this short time frame we will not attempt the more ambitious goal of optimization of the location of processing. Transparent management of files written into the Data Grid is a goal, but will not be a required deliverable of the first year.
The overall first-year goal is to achieve a production system serving data analysis of simulated and acquired data for physicists in at least two particle physics experiments, and to demonstrate interworking between all the participating particle physics sites. To accommodate the range of participating experiments we will develop a reference set of files and applications to publish the performance of the system. The LHC experiments (CMS — Caltech, Fermilab, and Atlas — ANL, BNL, LBL) are expected to participate significantly in this activity. They are generating large simulated file sets that will be used for the development and testing of physics applications across many university groups.
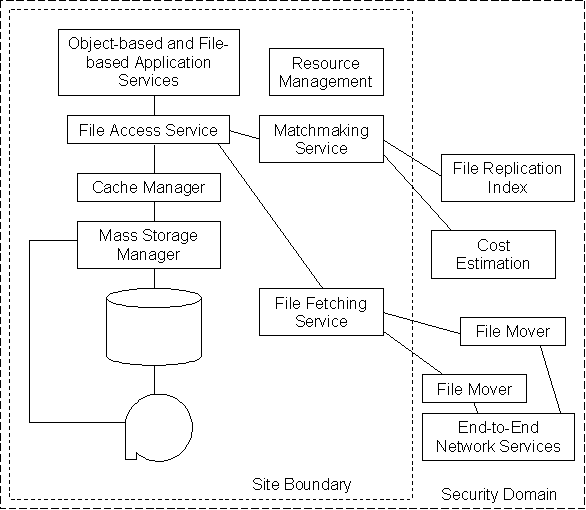
The diagram shows the main middleware components required to implement the two services described above, and the principal control flows involved. In brief: when the File Access Service determines that the requested file is not available locally it calls upon the Matchmaking Service to find the lowest cost way to retrieve the file. In its turn the Matchmaking service needs the File Replication Index to find out where copies already exist and the Cost Estimation service to determine which will be cheapest to retrieve. The File Fetching Service uses site-dependent movers to retrieve files. In the case of the high-speed file replication service, movers must be adapted to use the appropriate bulk transfer network service. Global resource management will not be a first-year deliverable, but first-year work will begin the deployment of resource discovery and management services.
The construction of a system with this degree of sophistication is possible because we can build on a substantial body of existing software. The initial choice of middleware components for the first year is:
Object-based and File-based Application Services |
Objectivity DB (plus SLAC/BaBar enhancements); |
Resource Management |
Starting point is human intervention |
File Access Service |
Components of OOFS (SLAC) |
Cache Manager |
Grand Challenge Cache Manager (LBNL) |
Mass-Storage Manager |
HPSS, Enstore, OSM (Site-dependent) |
Matchmaking Service |
Condor (U. Wisconsin) |
File Replication Index |
MCAT (SDSC) |
Transfer Cost Estimation Service |
Globus (ANL) |
File Fetching Service |
Components of OOFS (SLAC) |
File Mover(s) |
SRB, Storage Resource Broker, (SDSC); |
End-to-End Network Services |
Globus tools for end-to-end QoS reservation |
Security and Authentication |
Globus (ANL) |
Although we will use existing software for each component, we estimate that each will require up to one person-year of effort to adapt, interface and integrate.
Site |
CPU |
Mass Storage Management
Software |
Disk Cache |
Robotic Tape Storage |
Network Connections |
Network Access Speeds |
ANL |
100 |
HPSS |
>1 |
80 |
ESnet |
OC12 |
BNL |
400 |
HPSS |
20 |
600 |
ESnet |
OC3 |
Caltech |
100 |
HPSS |
1.5 |
300 |
NTON |
OC12-(OC48) |
Fermi Lab |
100 |
Enstore |
5 |
100 |
ESnet |
OC3 |
Jefferson Lab |
80 |
OSM |
3 |
300 |
ESnet |
T3-(OC3) |
LBNL |
100 |
HPSS |
1 |
50 |
ESnet |
OC12 |
SDSC |
|
|
|
|
CalREN-2 |
OC12 |
SLAC |
300 |
HPSS |
10 |
600 |
NTON |
OC12-OC48 OC3 |
U. Wisconsin |
~100 |
|
|
|
MREN |
OC3 |
We propose to install a 1 terabyte disk cache at Caltech funded by and dedicated to this project. This cache will allow development and testing that would be too disruptive to any of the other facilities. Apart from this cache, none of the above resources is funded by this project. Resources are considered relevant if, for example, they are being installed to meet the data-analysis needs of current high-energy and nuclear physics experiments that have a strong interest in the success of this project. We intend to integrate a substantial fraction of these resources into the Data Grid while ensuring that the users of these resources derive medium-term benefits outweighing short-term disruptions.
The network connections available for use in this project at each collaborating site are shown in the table above. Both MREN and CalREN-2 are proposing testbeds that will support QoS interworking with ESnet. NTON offers the complementary service of bandwidth limited only by the sophistication of the termination equipment placed at each site.
For early experiments with advanced network services, we hope to be able to exploit capabilities provided by both ESnet and by the EMERGE testbed proposed by the MREN community in response to DOE NGI 99-10. The latter proposed testbed will deploy differentiated service quality of service mechanisms, advanced instrumentation capabilities, and other Globus-based Grid services across both MREN sites and (in cooperation with DOE partners) ESnet sites; hence, it provides an excellent setting for large-scale evaluation of the technologies to be developed in this proposal, allowing us to take for granted the availability of required security, quality of service, resource management, and other mechanisms. PIs on the current proposal (Foster, Tierney) are very involved in the development of these services and so we expect the Data Grid to be an early user (and stress tester).
Site |
Liason
with MREN,CalREN-2, NTON (QoS and Bulk Transfer) |
Resource Management |
Integration
of Object-based and File-based Applications Services |
Integration of and enhancements to: |
|||||||||
File
Access Service |
Cache
Manager |
Mass-Storage
Managers |
Matchmaking
Service |
File
Replication Index |
Cost
Estimation |
File
Fetching Service |
QoS
Aware File Movers |
End-to-End
Network Services |
Security
and Authentication |
||||
ANL |
|
|
.75 |
|
|
|
|
|
|
|
|
.5 |
.25 |
BNL |
|
|
.25 |
.25 |
|
.25 |
|
|
|
|
|
|
|
Caltech |
.25 |
|
1 |
|
|
|
|
|
|
|
|
|
|
Fermi Lab |
|
.25 |
.5 |
|
|
.25 |
|
|
.25 |
|
|
|
|
Jefferson Lab |
|
|
.5 |
|
|
.25 |
|
|
|
|
|
|
|
LBNL |
.25 |
|
.5 |
.5 |
.5 |
|
|
.25 |
|
|
|
|
|
SDSC |
|
|
|
|
|
|
|
.5 |
|
|
.5 |
|
|
SLAC |
|
|
.5 |
.5 |
|
|
|
|
|
.5 |
|
|
|
U. Wisconsin |
|
.25 |
|
|
|
|
1 |
|
|
|
|
|
|
Project Start |
June 1, 1999 |
Decision on existing middleware to be integrated into the first-year Data Grid; |
August 1, 1999 |
First demonstration of high-speed site-to-site data replication |
November 1, 1999 |
First demonstration of multi-site cached file access (3 sites) |
December 1, 1999 |
Deployment of high-speed site-to-site data replication in support of two particle-physics experiments |
May 1, 2000 |
Deployment of multi-site cached file access in partial support of at least two particle-physics experiments |
June 1, 2000 |
The FY 2000 – FY2001 program of work will build on the experience of the first year and the middleware requirements that will be exposed. We intend to integrate the NGI-funded work into a much larger effort on distributed scientific data management. Particle-physics resources will be leveraged extensively, but we also aim to collaborate with a wider DoE and NSF-funded community of scientists facing the problems of distributed collaborative work on large volumes of data.
The focus on the rapid validation of ideas by offering real networked data management services to scientists with demanding and time-critical needs will remain. The short-term focus on the transport of read-only data to a location explicitly chosen by the user will be broadened. Transparent entry of data into the Data Grid will be essential and the Data Grid must become capable of selecting the most appropriate node on which to perform each task (‘agent technology’). The long-term goal of a Data Grid capable of handling ‘virtual data’ will be a guiding principle.
Some of the concepts that we consider relevant to planning the longer-term program of work are:
- The system should be resilient, predictive/adaptive and be aimed at maximizing workflow and minimizing response time for priority tasks;
- The system should use static and mobile autonomous agents to carry out well-defined tasks, thus reducing dependence on the network state through the agents' autonomy and reduced messaging between remote processes. Agent functions include resource profiling (by site and over time), network state tracking and capability prediction;
- Loose coupling and resilience should be achieved through the "large time quantum" appropriate for applications that are both data- and compute-intensive. The system need only predict the future capability of the network, compute and data storage and delivery services in average, over minutes to hours, not in real time from moment to moment. Coupled with appropriate workflow and transaction management mechanisms, this will make the prediction process reliable, and the overall system performance robust;
- Prioritization of tasks should be based both on policies (according to type of task, originating group, originating or destination site) and marginal utility (availability of resources; time to completion; age of process in the system, etc.). Cost estimators for completing a transaction will be developed to allow effective tradeoffs between policy-based priority and marginal utility-based priority, in cases where the two metrics for queuing tasks do not obviously agree;
- Co-scheduling algorithms ("matchmaking") should be used to match requests to resources within a time quantum, and the outcomes of matchmaking will affect indices used to measure marginal utility. Co-scheduling should use both metrics of proximity of the data — to the user and/or to the computing resources — and pre-emptive data movement for large data transfers and/or long computing tasks;
- Differentiated services should be used to segregate tasks with different times-to-completion, and different requirements for bandwidth, latency and perhaps jitter, into separate "performance classes". Examples of this include the separation of bulk-data-movement tasks from data analysis tasks frequently referencing smaller chunks of data. This will need to be generalized to accommodate interactive sessions, remote collaboration session including video and real-time shared applications, and intermediate analysis and re-reconstruction tasks using partially reconstructed data;
- Transaction management should utilize the cost estimators mentioned above, as well as checkpoint/rollback mechanisms. These mechanisms will have to be integrated with the applications in some cases. Application profiling (using tools embedded in the program code) may have to be used to characterize and/or predict an application's needs for I/O and other resources.
Specific tasks currently planned for FY 2000 – FY 20001 are:
Ę Development of a generalized file-mover framework that is aware of, and can effectively exploit the relevant types of network service including a high-priority, low latency service for control functions and multiple high latency (or scheduled availability) bulk transfer services;
Ę Implementation/generalization of the cataloging, resource broker and matchmaking services needed as foundations for both transparent write access and agent technology;
Ę Implementation of transparent write access for files;
Ę Implementation of limited support for ‘agents’: automatic scheduling of data analysis operations to the most appropriate CPUs at Data Grid sites;
Ę Implementation of distributed resource management for the Data Grid. This will require that network and storage systems at each site be instrumented to support resource discovery;
Ę Instrumentation of all Data Grid components in support of a systematic approach to measurement of and modeling of Data Grid behavior. Modeling studies are currently expected to be supported by other projects that will be closely coordinated with the work on the Data Grid;
Ę Major efforts on robustness and rapid problem diagnosis, both at the component level and at the architectural level;
Ę Continuing efforts to support the services, such as transparent support for persistent objects, most appropriate for end users performing data analysis. We expect that the majority of this support will come from other sources such as the particle-physics and other scientific programs. However, our focus on ensuring that useful services are really delivered will remain.
Site |
Liason
with |
Integration
of Object-based and File-based Applications Services |
Robustness |
Instrumentation |
Distributed
Resource Management |
Limited
Agent Support |
Transparent
Write Access |
Catalog,
Resource Broker, Matchmaking |
Generalized
QoS-aware File-Movement Framework |
|
ANL |
.25 |
.5 |
.5 |
|
.5 |
|
|
.5 |
.75 |
|
BNL |
|
1 |
.5 |
|
|
|
|
|
|
|
Caltech |
.5 |
.5 |
.5 |
|
|
1 |
|
|
|
|
Fermi Lab |
|
1 |
.25 |
.25 |
1 |
|
|
|
|
|
Jefferson Lab |
|
.75 |
.25 |
|
|
.5 |
|
|
|
|
LBNL |
.25 |
.5 |
1 |
.75 |
.5 |
|
1 |
|
|
|
SDSC |
|
|
.5 |
.5 |
|
|
|
1 |
|
|
SLAC |
|
1 |
.5 |
.5 |
|
|
.5 |
|
.5 |
|
U. Wisconsin |
|
|
.5 |
.5 |
|
|
|
1 |
|
|
The ambitious goals of this project
are possible because we can build on a strong base of software and expertise, in such
areas as high-performance networking, advanced networked middleware (e.g., Globus and
DPSS), scientific data management, and high-performance storage systems. These connections will continue as we pursue the
research goals addressed here, with, for example, other funding provided by DOE and other
agencies to further develop PCMDI data analysis systems and to continue Globus
development.
More broadly, we view the research
described here as forming a key component of a larger activity designed to develop and
apply an Integrated Grid Architecture. This integrated architecture comprises four
principal components (for more detail, see www.gridforum.org/iga.html):
1.
At the Grid Fabric level, primitive mechanisms provide
support for high-speed network I/O, differentiated services, instrumentation, etc.
2.
At the Grid Services or middleware
level, a suite of Grid-aware services implement basic mechanisms such as authentication,
authorization, resource location, resource allocation, and event services.
3.
At the Application Toolkit level, toolkits provide more
specialized services for various applications classes: e.g., data-intensive, remote
visualization, distributed computing, collaboration, problem solving environments.
4.
Finally, specific Grid-aware applications are implemented in terms of
various Grid Services and Application Toolkit components.
The project proposed here will
contribute to this overall architecture at multiple levels.
At the fabric and services levels, we will contribute to an understanding of
how to support very high bandwidth flows and how to perform resource management to achieve
end-to-end performance. At the application
toolkit level, we will contribute to the development of distributed computing and data
management toolkits. This work directly
supports existing and proposed DOE research activities concerned with distributed
computing (e.g., distance corridors, climate modeling, materials science). It also complements existing and proposed DOE
research activities concerned with networking technology and middleware: in particular,
those concerned with resource management and quality of service, instrumentation, and
network topology determination. We will also
be relying on testbed capabilities provided by ESnet, the sites participating in the
Globus Ubiquitous Supercomputing Testbed Organization (GUSTO), and, we expect, the proposed EMERGE and CalREN2 testbeds.
The proposed research is also highly
relevant to the goals of the SSI and ASCI projects. In addition to addressing directly key
requirements of the SSI Global Systems component, we will develop technologies of high
relevance to ASCI DISCOM and Distance Corridor efforts.
The work will also implement tools that will be applicable to other SSI
application areas (e.g., Combustion) which have a need for high-bandwidth transport and
management of and access to large amounts of data.
Technology from this project will be transferred to DOE application scientists and to scientists further afield. This will occur through the already successful HEP and Globus software distribution mechanisms; via the various linkages noted above; and via the strong ongoing collaborative links that exist between the participants and other programs, in particular the NSF PACIs, DARPA, and the NASA Information Power Grid program.
The management structure we propose will exist to facilitate the intention of the partners to overcome the naturally divergent forces that exist in a collaboration between many sites and between two very different scientific disciplines. The management model is based on those of successful collaborations in particle physics, paying special attention to projects with a strong software focus that have succeeded in the absence of top-down financial control. This management structure can be considered as a prototype for the ‘Virtual Centers’ that will be essential for coordinated progress on SSI infrastructure.
The collaborators on this proposal include leading computer scientists at DoE laboratories and universities, the scientists in charge of computing and data handling at the four DoE particle-physics accelerator laboratories, and the leaders of the US-based computing efforts for the Atlas and CMS experiments.
Management will be effected through two boards:
1. Collaboration
Board (CB):
This board sets long-term strategy and ensures that the project has appropriate resources
at each site. It will normally consist of the
local project PI from each collaborating site. The
members must be the people with authority over the project resources and must also control
the local programmatic (particle-physics or CS) resources whose leverage is vital to this
project. We believe that appropriate persons
are already collaborating on this proposal. The
CB will meet 2 or 3 times per year, mostly by video conference.
2. Technical
Steering Board (TSB):
This board provides the technical management for the project. It consists of at least one person per site
representing the sites principal scientific and technical contributions to the project. The TSB is responsible for the month-to-month
steering of the project, bringing only major resource-related concerns to the CB for
resolution. The members of the TSB act as
local project managers and the TSB will identify task forces for the many multi-site
components of the project. The TSB will meet
monthly, mostly by teleconference or videoconference.
The members of the CB and TSB are likely to overlap significantly, but the two management functions will be clearly distinguished.
Initial membership of the CB and TSB will be:
|
Collaboration Board |
Technical Steering Board |
ANL |
Lawrence Price |
Ian Foster (Chair) |
BNL |
Bruce Gibbard |
Torre Wenaus |
Caltech |
Harvey B. Newman (Chair) |
Julian Bunn |
Fermilab |
Victoria White |
Ruth Pordes |
LBNL |
Stewart C. Loken |
Arie Shoshani |
SDSC |
Margaret Simmons |
Reagan Moore |
SLAC |
Richard Mount |
Andrew Hanushevsky |
Jefferson Lab. |
Chip Watson |
Ian Bird |
U. Wisconsin |
Miron Livny |
Miron Livny |
[BFKTT99] Joseph Bester, Ian Foster, Carl Kesselman, Jean Tedesco, Steven Tuecke, GASS: A Data Movement and Access Service for Wide Area Computing Systems, Proc. IOPADS'99, ACM Press, 1999.
[BFLM+96] Chaitanya Baru, Richard Frost, Joseph Lopez, Richard Marciano, Reagan Moore, Arcot Rajasekar, Michael Wan, Meta-data design for a massive data analysis system, Proceedings CASCON '96, November 1996.
[BL99] (Jim Basney and Miron. Livny) High Throughput Monte Carlo, the Proceedings of the Ninth SIAM Conference on Parallel Processing for Scientific Computing, March 22-24, 1999, San Antonio, Texas.
[BMRW98] Chaitanya Baru, Reagan Moore, Arcot Rajasekar, Michael Wan, The SDSC Storage Resource Broker, Proceedings of CASCON'98 Conference, Toronto, Canada, December 1998.
[BMRS+98] Chaitanya Baru, Reagan Moore, Arcot Rajasekar, Wayne Schroeder, Michael Wan, Rick Klobuchar, David Wade, Randy Sharpe, Jeff Terstriep, A data handling architecture for a prototype federal application, Sixth Goddard Conference on Mass Storage Systems and Technologies, March 1998.
[BNRS98] L. Bernardo, H. Nordberg, D. Rotem, and A. Shoshani, Determining the Optimal File Size on Tertiary Storage Systems Based on the Distribution of Query Sizes, Tenth International Conference on Scientific and Statistical Database Management, 1998, (http://www.lbl.gov/~arie/papers/file.size.ssdbm.ps).
[Bir97] Ken Birman, Building Secure and Reliable Network Applications, Manning, 1997.
[B+98] J. Bakken et.al . “Requirements for the Sequential Access Model Data Access System”, Technical Report JP0001, Fermilab, 1998. (http://RunIIComputing.fnal.gov/sam/doc/requirements/sam_vw_req_arch.ps)
[B+99] J. Bakken, E. Berman, C. Huang, A. Moibenko, D. Petravck, R. Rechenmaker, K. Ruthmansdorfer, “Enstore Technical Design Document”, Technical Report JP0026, Fermilab, 1999. (http://www-hppc.fnal.gov/enstore)
[CDLK+95a] L.T. Chen, R. Drach, M. Keating, S. Louis, D. Rotem, and A. Shoshani, Optimizing Tertiary Storage Organization and Access for Spatio-Temporal Datasets, NASA Goddard Conference on Mass Storage Systems, March 1995, (http://www.lbl.gov/~arie/papers/optimass.goddard.ps).
[CDKL+95b] L.T. Chen, R. Drach, M. Keating, S. Louis, D. Rotem and A. Shoshani, Efficient Organization and Access of Multi-Dimensional Datasets on Tertiary Storage Systems}, Information Systems Journal, Pergammon Press, April 1995, vol. 20, (no. 2): 155-83. (http://www.lbl.gov/~arie/papers/optimass.Info.Sys.ps).
[CFNK+98] K. Czajkowski, I. Foster, N. Karonis, C. Kesselman, S. Martin, W. Smith, and S. Tuecke. A resource management architecture for metacomputing systems. In The 4th Workshop on Job Scheduling Strategies for Parallel Processing, pages 62-82. Springer-Verlag LNCS 1459, 1998.
[CFK99] . Czajkowski, I. Foster, and C. Kesselman, Co-Allocation Services for Computational Grids. Proceedings of the IEEE Symposium on High-Performance Distributed Computing, 1999.
[FFKL+97] S. Fitzgerald, I. Foster, C. Kesselman, G. von Laszewski, W. Smith, and S. Tuecke, A Directory Service for Configuring High-performance Distributed Computations, Proc. 6th IEEE Symposium on High-Performance Distributed Computing, 365-375, IEEE Press, 1997.
[FK98] I. Foster and C. Kesselman, The Globus Project: A Status Report, Proceedings of the Heterogeneous Computing Workshop, IEEE Press, 4-18, 1998.
[FK99b] I. Foster and C. Kesselman. Globus: A Toolkit-Based Grid Architecture. In The Grid: Blueprint for a Future Computing Infrastructure, pages 259-278. Morgan Kaufmann Publishers, 1999.
[FKTT98] I. Foster and C. Kesselman and G. Tsudik and S. Tuecke, A Security Architecture for Computational Grids, ACM Conference on Computers and Security, 83-91, ACM Press, 1998.
[FKL+99] Ian Foster, Carl Kesselman, Craig Lee, Bob Lindell, Klara Nahrstedt, Alain Roy, and Steven Tuecke, A Distributed Resource Management Architecture that Supports Advance Reservations and Co-Allocation, submitted, 1999.
[HJFR98] G. Hoo, W. Johnston, I. Foster, and A. Roy, QoS as middleware: Bandwidth broker system design, Technical report, LBNL, 1999.
[HN99] A. Hanushevsky and M. Nowak, "Pursuit of a Scalable High Performance Multi-Petabyte Database", in Proceedings of the 16th IEEE Symposium on Mass Storage Systems, pp 169-175, March 1999.
[L+97] L. Lueking for the D0 Collaboration, “D0 Run II Data Management and Access”, Proceedings of Computing in High Energy Physics 1997 (CHEP97)
[LW+98] L. Lueking, F. Nagy, H. Schellman, I. Terekhov, J. Trumbo, M. Vranicar, R. Wellner, V. White, “The Sequential Access Model for Run II Data Management”, in Proceedings of Computing in High Energy Physics 1998 (CHEP98).( http://RunIIComputing.fnal.gov/sam/doc/talks/1998CHEP/chep98.ps)
[LR99] Miron Livny and Rajesh Raman, High Throughput Resource Management. In The Grid: Blueprint for a Future Computing Infrastructure, pages 311-337, Morgan Kaufmann Publishers, 1999.
[MBMRW99] Reagan Moore, Chaitanya Baru, Richard Marciano, Arcot Rajasekar, Michael Wan, Data-Intensive Computing. In The Grid: Blueprint for a Future Computing Infrastructure, pages 105-129. Morgan Kaufmann Publishers, 1999.
[P+98] D. Petravick, et. al., “Enstore, an Alternate Data Storage System”, Presented at Computing in High Energy Physics 1998 (CHEP98) 1998.
[RLS98]
Rajesh Raman, Miron Livny and Marvin Solomon, Matchmaking: Distributed Resource Management
for High Throughput Computing," Proceedings
of the Seventh IEEE International Symposium on High Performance Distributed Computing,
July 28-31, 1998, Chicago, IL.
[SBNRS98] A. Shoshani, L. M. Bernardo, H. Nordberg, D. Rotem, and A. Sim, Storage Management for High Energy Physics Applications, Computing in High Energy Physics 1998 (CHEP 98), (http://www.lbl.gov/~arie/papers/proc-CHEP98.ps).
[SBNRS99] A. Shoshani, L. M. Bernardo, H. Nordberg, D. Rotem, and A. Sim, Storage Management Techniques for Very Large Multidimensional Datasets, February 1999, Submitted for publication.
[STACS99] The Storage Access Coordination System (STACS): http://gizmo.lbl.gov/sm/
[TJH94] B TierŁney, W Johnston,
H Herzog, G Hoo, G Jin, J Lee, System Issues in Implementing High Speed Distributed
Parallel Storage Systems , Proceedings of the USENIX Symposium on High Speed Networking,
Aug. 1994, LBL-35775.
[TJC98] B. Tierney, W. Johnston, B. Crowley, G. Hoo, C. Brooks, D. Gunter, “The NetLogger Methodology for High Performance Distributed Systems Performance Analysis,” Seventh IEEE International Symposium on High Performance Distributed Computing, Chicago, Ill., July 28-31, 1998. (http://www-itg.lbl.gov/DPSS/papers.html).
[VW+98] V. White et. al., “Use of Oracle in Run II
for D0”, Poster presentation at Computing in High Energy Physics 1998 (CHEP98)
, 1998,
(http://d0server1.fnal.gov/users/white/talks/CHEP98-Oracle/ChepPoster-Oracle/index.htm)
[ZJN97] L. Zhang, V. Jacobson, and K. Nichols, A two-bit differentiated services architecture for the internet. Internet Draft, Internet Engineering Task Force, 1997.