|
|
Problems with performance between SLAC and IN2P3, Jan '02
Les Cottrell Page created:
January 8, 2002, last update March 4, 2002.
|
IN2P3 announce only the 194.5.57.0 network to ESNET on this link (for the moment the only machine concerned is ccb2sn04.in2p3.fr). So the traffic from SLAC to CCIN2P3 goes through the CERN link except to ccb2sn04 where it uses the RENATER path, and the traffic from CCIN2P3 to SLAC uses the CERN link except for ccb2sn04 to DATAMOVE33.SLAC.Stanford.EDU where it uses the RENATER VP (we have a static routing for this).
Jerome Bernier, IN2P3 Nov 29 2001.Traceroute shows the route and AS'. It confirms that the route at this time did not go via CERN. Pipechar was used to measure the bottleneck from hercules.slac.stanford.edu to ccb2sn04.in2p3.fr. Hercules is a 2*1131 MHz Linux 2.4 host with 2 GE interfaces. Pipechar indicates a limit of about 46Mbps between the ESnet router in Chicago (chi-s-snv.es.net) and the 192.70.69.14 (192.70.69.14) [AS1717 - PHYNET-INTER] router, and a limit of about 30Mbits/s between the last router (Lyon-ANDA.in2p3.fr) and ccb2sn04. So at least from this point of view things look good.
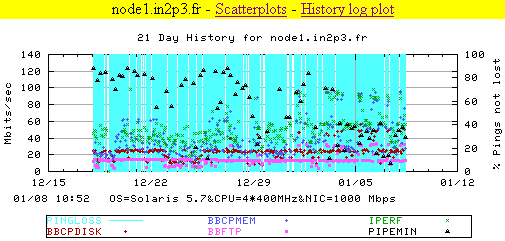
We have now extended the IEPM-BW monitoring to also monitor the SLAC-ESNET-RENATER-IN2P3
link on a regular basis. We also used tcpload.pl to measure the throughput for various
window sizes and streams (see
Bulk throughput measurements
for details of the measurement methodology) from pharlap.slac.stanford.edu
(a Solaris 5.8 host with 4*336 MHz cpus) to
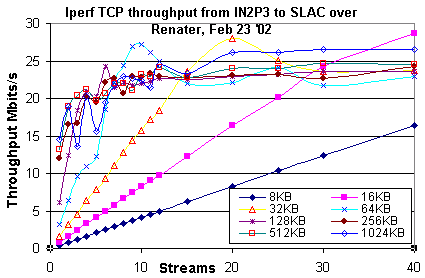
ccb2sn04.in2p3.fr. The maxima (top 10% throughputs) are over 18.25Mbits/s, and the
maximum achieved was 21.43 Mbits/s. The details can be seen in the plot below.
We repeated the tcpload.pl measurement from hercules.slac.stanford.edu
to ccb2sn04.in2p3.fr with very similar results.

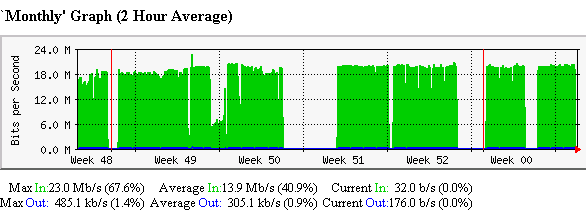
The monitoring of the IN2P3 RENATER link from IN2P3 indicates that the utilization
is currently about 20Mbits/s, however the measurements of June and September
showed they could sustain close to 30 Mbits/s, see below (from
Trafic IN2P3/ESnet).
Looking at the tcpdump output it is clear that the window sizes and MTU discovery are working OK.
Joe Metger <JMetzger@lbl.gov> responded on Jan 9 '02 Thanks for generating the trace files! We have been looking at this problem and it is not a straight forward issue of a PVC shaped at 20 Mbps (at least on the ESnet links). My current suspicion is that the flow exceeds a queue limit somewhere along the path that is generating packet loss and the drop in performance. Hopefully the trace files your providing will help us to determine if this is the cause and give us a better idea of the exactly what we should be looking for.
> 6 Lyon-INTER.in2p3.fr (192.70.69.14) [AS1717 - PHYNET-INTER] 168 ms
CCIN2P3 Site LAN
GigE
No policing or shaping
> 7 Lyon-ANDA.in2p3.fr (134.158.224.1) [AS789 - Institut National de Physique
> Nucleaire et de Physique des Particules] 195 ms
CCIN2P3 Site LAN
FastE
No policing or shaping
>
> 8 ccbbsn04.in2p3.fr (134.158.104.74) [AS789 - Institut National de Physique
> Nucleaire et de Physique des Particules] 169 ms
The only information that i am not sure is the configuration
of the VP between
AADS Chicago and us.
Renater people already told me that it is a 30Mbps VP (with 40Mbps peak)
but this VP is crossing several switches with several configurations
so i have asked them to re-re-check the VP configuration.
As far as understanding the various link components (this is from a series of emails between Les Cottrell and Gary Buhrmaster of SLAC, Joe Metzger of ESnet, and Jerome Bernier of IN2P3):
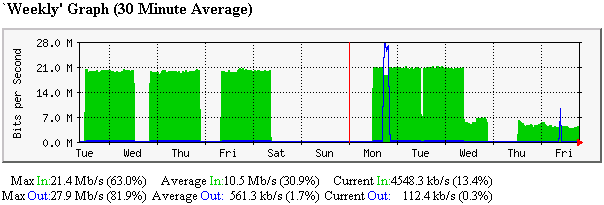 We are now down to 4.5 Mb/s.
We are now down to 4.5 Mb/s.
cbbsn04:tcsh[34] traceroute datamove33.slac.stanford.edu traceroute: Warning: Multiple interfaces found; using 134.158.104.74 @ ge0 traceroute to datamove33.slac.stanford.edu (134.79.125.253), 30 hops max, 40 byte packets 1 Lyon-ANDA.in2p3.fr (194.5.57.1) 1.167 ms 0.773 ms 0.724 ms 2 Lyon-INTER.in2p3.fr (134.158.224.4) 24.430 ms 0.981 ms 0.940 ms 3 192.70.69.13 (192.70.69.13) 120.463 ms 120.455 ms 120.580 ms 4 snv-s-chi.es.net (134.55.205.101) 168.731 ms 168.318 ms 169.043 ms 5 slac-pos-snv.es.net (134.55.209.2) 169.221 ms 168.987 ms 169.077 ms 6 RTR-DMZ1-VLAN400.SLAC.Stanford.EDU (192.68.191.149) 169.001 ms 168.699 ms 168.647 msThen I started some iperf servers on datamove33 and ran iperf for 10 seconds many times with different windows and stream sizes from ccbbsn04 to datamove33:
18cottrell@datamove33:~>traceroute CCB2SN04.IN2P3.FR traceroute: Warning: ckecksums disabled traceroute to CCB2SN04.IN2P3.FR (194.5.57.104), 30 hops max, 40 byte packets 1 RTR-FARMCORE1A.SLAC.Stanford.EDU (134.79.127.7) 0.550 ms 0.408 ms 0.382 ms 2 RTR-DMZ1-GER.SLAC.Stanford.EDU (134.79.135.15) 0.361 ms 0.305 ms 0.307 ms 3 192.68.191.146 (192.68.191.146) 0.361 ms 0.351 ms 0.339 ms 4 snv-pos-slac.es.net (134.55.209.1) 0.761 ms 0.710 ms 0.732 ms 5 chi-s-snv.es.net (134.55.205.102) 48.747 ms 48.815 ms 48.791 ms 6 192.70.69.14 (192.70.69.14) 149.914 ms 149.556 ms 167.480 ms 7 Lyon-ANDA.in2p3.fr (134.158.224.1) 149.755 ms 155.322 ms 151.614 ms 8 ccb2sn04.in2p3.fr (194.5.57.104) 150.993 ms * 151.876 msThe results of 10 second iperf measurements with various windows and streams look as follows:
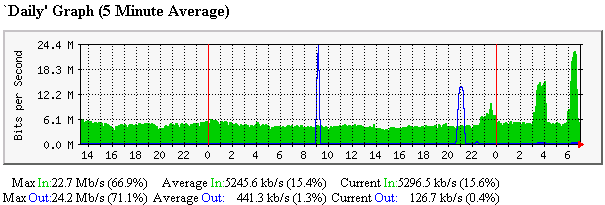
Using bbcp to make disk to disk copy of an uncached 60MByte Objectivity file to /de/null, with 40 streams and an 8KByte window, I was able to achieve just over 11Mbits/s. I then ran bbcp memory to memory for about an hour and the throughput in the MRTG plot went up to about 14-15 Mbits/s, at this time bbcp was reporting throughput of about 1183KB/s or 9.46 Mbits/s. Possibly bbcp was adding its traffic to another application which was for some reason constrained to transmit about 5-6 Mbits/s.
I then ran iperf for 20 seconds with 40 streams and a window size of 8Kbytes, and measured a throughput of about
15-16 Mbits/s. I repeated this with 2 separate iperf clients each with 40 streams and an 8KByte window.
the aggregate throughput was again about 15-16 Mbits/s. So doubling the number of streams from 40 to 80
had little effect. In order to see the effect on the MRTG plot I then ran iperf for 30 minutes
with 40 streams and an 8Kbyte window. The maximum throughput recorded by MRTG was about 22.7Mbits/s,
and iperf recorded an average throughput of about 17 Mbits/s.
Below is seen the MRTG plot showing the impact of the bbcp measurement from 3-4 am, and the iperf
measurement just after 6am.
The datamove33 window sizes are:
ndd /dev/tcp tcp_max_buf = 1048576 ;ndd /dev/tcp tcp_cwnd_max = 1048576 ;ndd /dev/tcp tcp_xmit_hiwat = 16384 ;ndd /dev/tcp tcp_recv_hiwat = 24576and for ccbs2sno4 (= ccbbsn04, apart from how routing is done) are:
ndd /dev/tcp tcp_max_buf = 4194304 ;ndd /dev/tcp tcp_cwnd_max = 2097152 ;ndd /dev/tcp tcp_xmit_hiwat = 65536 ;ndd /dev/tcp tcp_recv_hiwat = 65536Thus my conclusion is that if there is an application generating the 5-6 Mbits/s background traffic, then it's throughput is limted by something other than the network in this case. Possibly it does not have enough streams. If the optimum number of streams was deduced from measurements made earlier (e.g. before or around January 8 '02) and the behavior of throughput with streams and windows changed so streams are now much more effective than windows, then this would account for today's poor performance. I do not currently have a hypothesis for why the throughput behavior with streams and windows should have changed. Also note that the above only explains the poor performance of the application that started around midday on Wednesday February 20th French time. It does not explain the apparent rate limiting around 20-22 Mbits/s that was initially reported.
Though I doubt it will make much difference I also recommend that the SLAC Unix administrators increase the window size on datamove33 to be the same as for IN2P3.
But the point here is that _in_the_same_conditions_ the transfer rate dropped from 20 Mbit/s to ~5 Mbit/s, the fact that you are able to get 11 with bbcp and optimized parameters clearly shows that the problem is _not_ due to rate policing somewhere.
I remember that last time we got the same kind of troughput drop, it was due to something queuing the packets on the ESNET side instead of dropping them (sorry if I am not using the right terminology !!! ) Could it be the same problem here ?
To summarize, we have probably 2 problems here: - The first one is the limitation to 20 Mbit/s that ESNET is interpreting as a rate policing on the RENATER side.
- The second one is the limitation from 20 to 5 Mbit/s for an unkown reason.
Would it be possible to have the e-mail of a RENATER responsible person to put him in the loop ? I have added Denis Linglin and Francois Etienne in the recipient list, I hope that escalating this problem in the French side will help.
shaping {
vbr peak 40m sustained 30m burst 200;
queue-length 980;
}
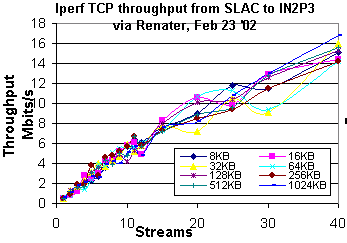
The throughput achievable now with iperf is shown below:

