Binary Archive Format
Directory File
The ArchiveEngine is started with the name of a directory file. If you omit the "directory file" command-line argument, it defaults tofreq_directory. All retrieval tools use
the name of this directory file to get at the archived data.
Note that in here directory file stands for a file name, not a
directory name. The file itself is called a "directory file".
Data Files
The directory file holds channel names and information about each channel, but not archived data. The data is stored in data files. By default, the ArchiveEngine creates one data file per day. Each data file name resembles the date when that data file was created, e.g.20000301-000000.
You cannot directly use a single the data file but only
the combination of all data files and the directory file,
the latter is given to the retrieval tools.The ArchiveManager is a tool for maintaining the combination of directory and data files.
MultiArchive
If you want to look at more than one archive, you could run the retrieval tools on all the directory files of interest. Alternatively, there is the "MultiArchive" option: Create a text file like this one:master_version=1 # First check the "fast" archive /archives/fast/dir # Then check the "main" archive /archives/main/dir # Then check Fred's "xyz" archive /home/fred/xyzarchive/dirand pass the name of this file to the retrieval tool instead of an individual directory file. For more details, see the MultiArchive description in the LibIO.
Binary Archive Details
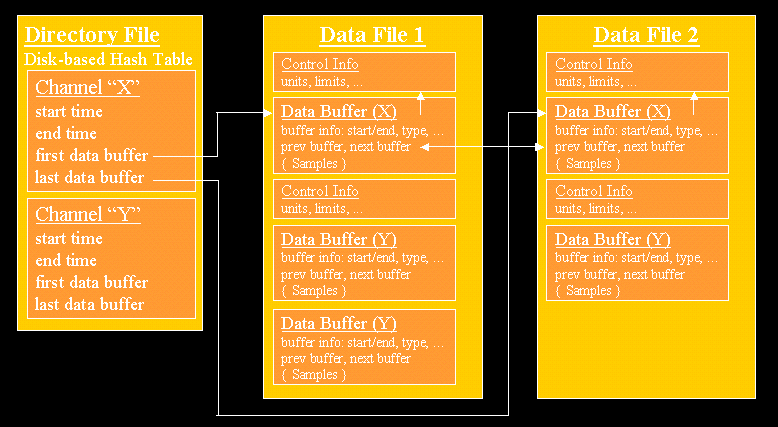
An easy approach to archiving would be this: For each channel, create an ASCII file and append new values to that file. This format is easy to maintain. Problem: The number of open files is quite limited on all operating systems. The archiver would have to open each file, append values, close it and move on to the next channel. This is much too slow!Therefore the idea of the ChannelArchiver is to write all channel data into a single file. Since files have a limited size, this is not really practical, so new data files are created, per default one per day. To keep track of the data file and the position of each channels' data in these files, a directory file is used.
We assume that adding new values is a common operation. For retrieval, we are most interested in recent values, since they are often requested at e.g. the end of an operational shift or for weekly summaries. Therefore the directory file has pointers to the last data buffer inside the data files for each channel. But we might also want to dump all the data for a channel, beginning with the first sample, which is why the directory file does also hold the pointer to the first data buffer for each channel.
To provide quick access to this per-channel information, given the channel name, the channel names are kept in a disk-based hash table, the directory file, per default called
freq_directory.
In addition to the channel name is contains the the first and last
available time stamp and the location of the first and last data
buffer for each channel in the date files.
As for a the data, one file per day (default) is used.
Separate buffers are used for control information (limits, units, ...) and the values (time stamp, status, raw value). When a data buffer for a channel is full, a new one is appended. The same control information buffer is referenced unless a portion of the control information has changed. A data file will be updated until all the buffers in there are filled. If a buffer is full and the threshold for creating a new data file is reached (per default: one day), a new data file is added. Therefore the filename of a data file merely reflects the date of creation, not the time regime of samples therein.
Advantage: This format allows archiving of up to 10000 values per second on a 450 Mhz machine, 100baseT network. Fast retrival to the most recent values is accomplished via the hash table and a pointer to the last entries.
Disadvantage: The combination of directory- and data-files must not
be disturbed!
Under no circumstances must any single data file be removed or
altered, since this will break the interlinked sequence of samples.
Note that this is not uncommon for database systems, but unfortunately the
data management tools for the ChannelArchiver are limited for the
time being.
Common Questions
- Data files grow/don't grow
Each data file has buffers, that is: reserved regions. Initially, one buffer per channel is reserved. When a buffer has been filled with samples, a new buffer is created. Each new buffer has twice the previous buffer's size (up to a limit). This means: The data file size will "jump" whenever a new buffer is allocated and then stay constant while buffers are filled. Ways to check wether the ArchiveEngine is still working: Check the ArchiveEngine's status. Does it still respond via the web interface? If any new data arrived that's worth writing, the time stamp of the latest data file should change at each write period. - Setpoint channels: invalid or old time stamps
Many EPICS databases contain "setpoints":
Passive channels that are only changed from an operator interface.
After booting an IOC, these channels have no valid time stamp. The archive engine might issue a warning, but these channels cannot be archived because of the invalid time stamp.
As soon as the setpoint is actually changed from an operator interface, the value is of course archived. But since it might not be changed often, its time stamp can be "old".
Consequence:
When you start the engine and get warnings about "invalid" time stamps or find that data files for "old" samples are created, this is the common reason. - Old data files are updated:
Data files are updated until the buffers in there are filled. Only then a new file might be created after e.g. 24 hours (default).
Consequence:
When you see that "old" data files still change, this is the reason. - Size of data files:
The ChannelArchiver saves this information for each channel:- value in its native type (double, int, array, string, ...)
- time stamp: This is the original time stamp that the IOC
sends in nanosecond resolution!
(Don't confuse this with other tools that take the current time of the computer that's running the sampling engine.) - status/severity
- Control Information: display limits, alarm limits, control limits, engineering units, enumeration strings for enumerated values
When archiving a channel with float values and the control information does not change, this results in about 16 bytes per value.
ChannelArchiver Manual