PingER Measurement Pathology Examples
Page created May 23, 1999 by:
Les Cottrell.
Last Update
July 16 2002.
Introduction
Using ping to measure LAN performance, we have encountered a
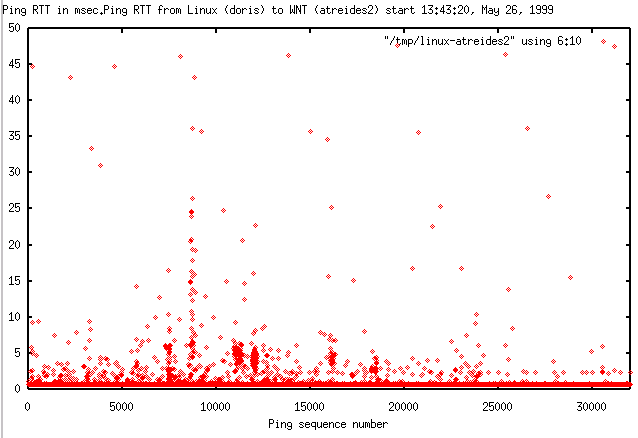
pathology when pinging from doris (Linux) to atreides (Windows NT).
The pathology manifested itself in the plot of ping RTT versus ping sequence
number as an unusual regularity in the sequence number separation of the
pings with RTT > 10 msec., see the highlighted link for
Linux to WNT (atreides)
below. The effect was reproducible.
In this page we provide an index to some interesting plots created when
tracking down the pathology. In the
case of Linux sending the ping requests the requesting host was
doris.slac.stanford.edu which was running Redhat Linux 5.2. The Windows NT
(WNT) hosts were running Windows NT 4 with Service Pack (SP) 4.
Some of the PC hosts could dual boot and so may show up as
running WNT or Linux. The Sun host (gryphon)
was running Solaris 5.6. The names
of the hosts involved are given in parentheses, are all in the
.slac.stanford.edu domain, and all, including doris,
are on the same subnet (PUB6). Also all hosts are on 10 Mbps shared Ethernet
hubs.
Unless otherwise noted the ping application was
the standard version delivered with the operating system. The pings were sent once a second,
had a timeout of 20 seconds, and contained 100 bytes.
All the graphs show the ping sequence number along the
x-axis (unless otherwise noted) and the ping round trip time (RTT) in
milliseconds
along the y axis.
Pinging involving PCs
Ping from Linux to WNT
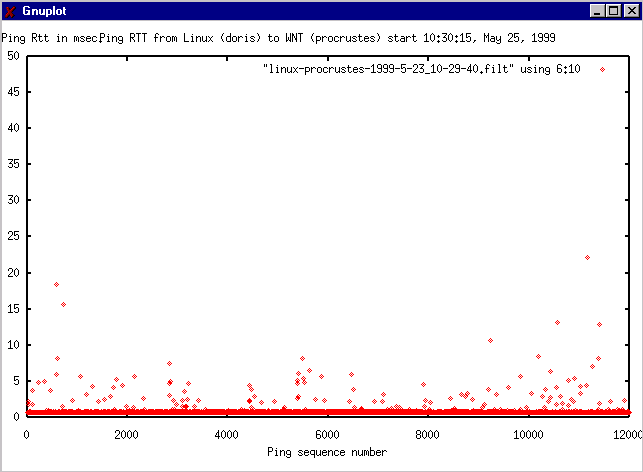
- Linux to WNT (procrustes)
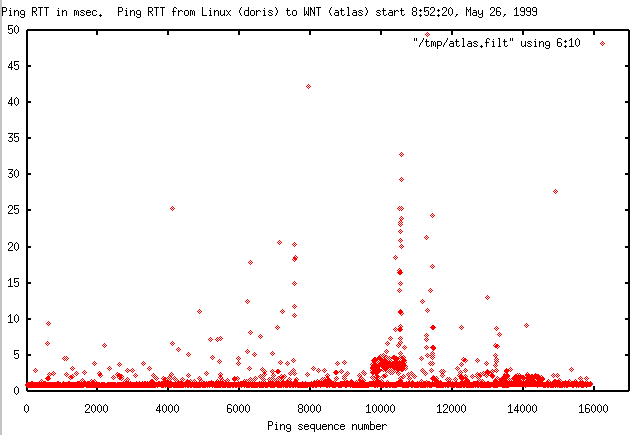
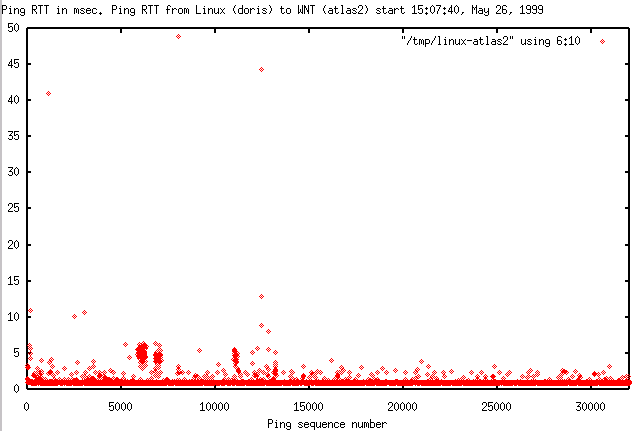
- Linux to WNT (atlas)
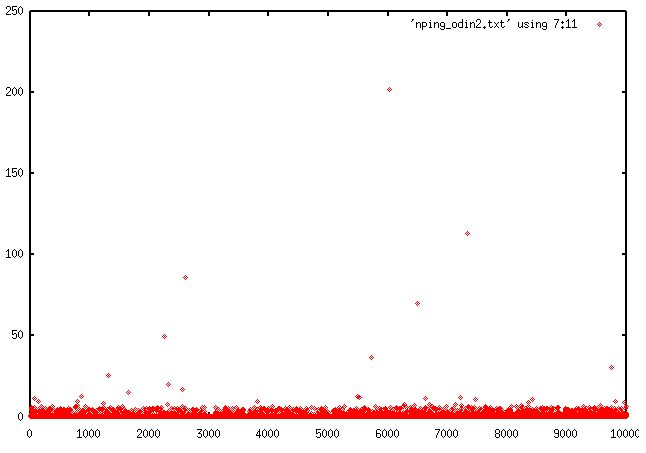
- The following two graphs are for pings from a Linux host (doris)
on one Catalyst 5000 switch port,
to two
different WNT hosts on a shared hub on a different switch
port to the one for
doris.
- We temporarily swapped the hub ports for atlas and atreides and the effect appears to
follow the host, rather than the port:
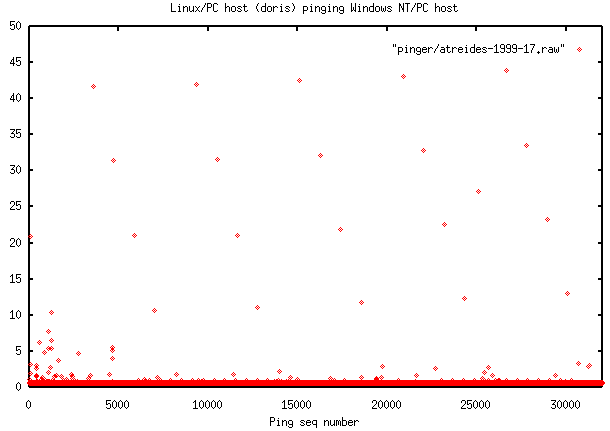
- Linux to WNT (atreides on atlas' hub port)
though the regularity is not as marked as
in the previous ping graph between
Linux and atreides, it is apparent especially for the 18 points
with RTT > 15 msec. and sequence
number > 13000. For these 18 points, 9 are separated by 1141 in
sequence number and 3 by
2342. The "wire-times" (as measured by NetXray running on atreides)
for the 12 pings with sequnce
number separation of 1141 or 2342 were
all < 200 usec.
- Linux to WNT (atlas on atreides' hub port).
- We installed the Linux host (doris) on the same 10Mbps shared hub (TT-CGB8 a
Centercom model 3624TR) as
the WNT host (atreides) and repeated the pings.
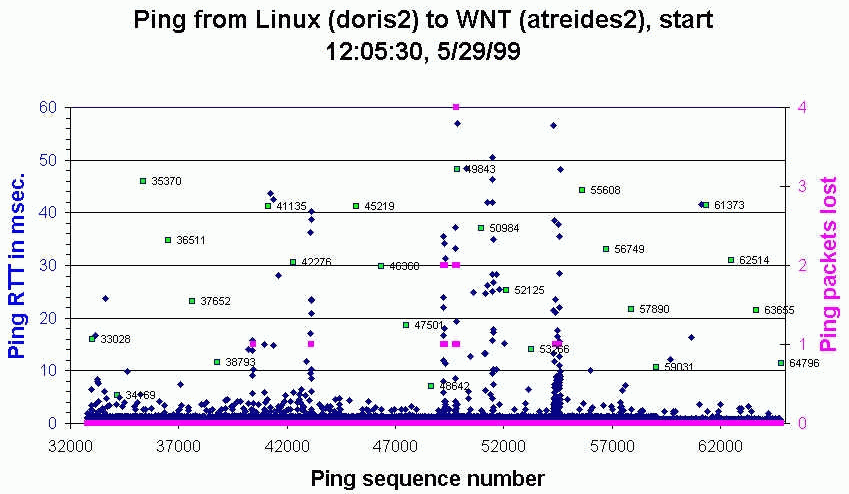
- Linux to WNT (atreides) on same hub
though much noisier the regularity is still observable.
The green dots are the pathologically regular RTTs with their sequence number
identified. For these 50 pathologically regular points, 36 are separated in sequence number by 1141,
3 by 2342, and 7 by 1201. Looking at the RTTs difference for adjacent
pathologically regular points,
over 80% lie in the range 10-12 msec.
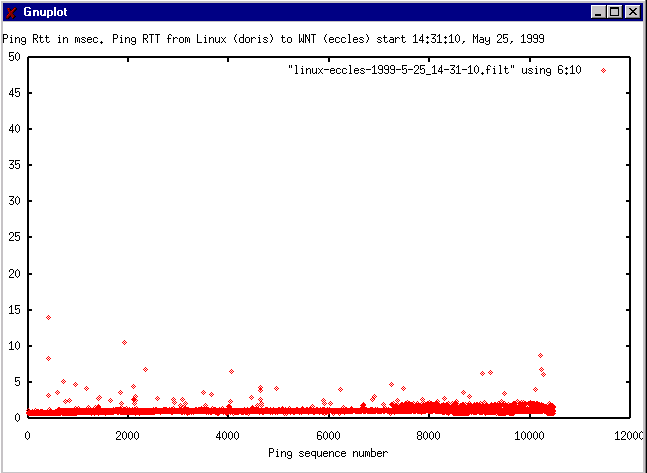
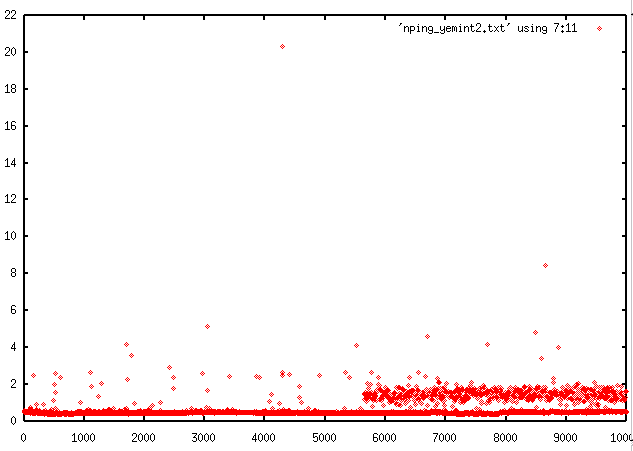
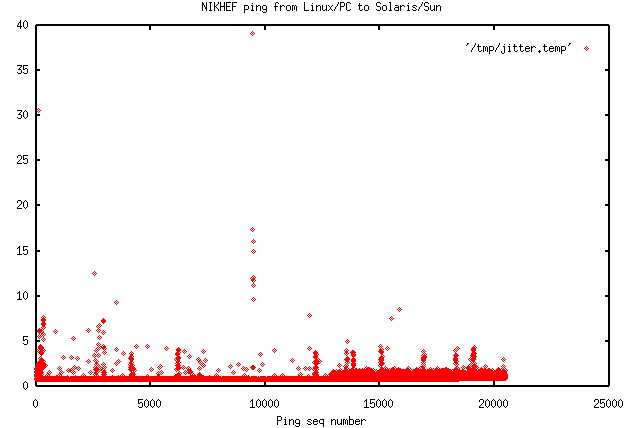
- NIKHEF ping Linux to
WNT (yemint) both hosts on
same shared 10 Mbps hub.
WNT to Linux
-
Windows NT (hector) to Linux. The graph shows the results from 32K pings.
Note that the
WNT ping RTT resolution is not better than 10 msec.,
i.e. ping on WNT reports > 10 ms as the smallest RTT. Also of all the 36 pings
reporting > 11 ms RTT only two were not a multiple of 10
(91 & 151 were the RTTs reported). Since WNT ping does
not report the sequence number, the x value is the ping output line number.
Included in these line numbers were 9 lines that said "Request timed out."
Looking at the separation of the line numbers of the pings with > 11 ms RTT
there is not an obvious pattern.
- Windows NT (atreides) to Linux. The graph
shows 32K pings, all pings reported as >10ms are plotted as 9 msec.
Linux to Linux
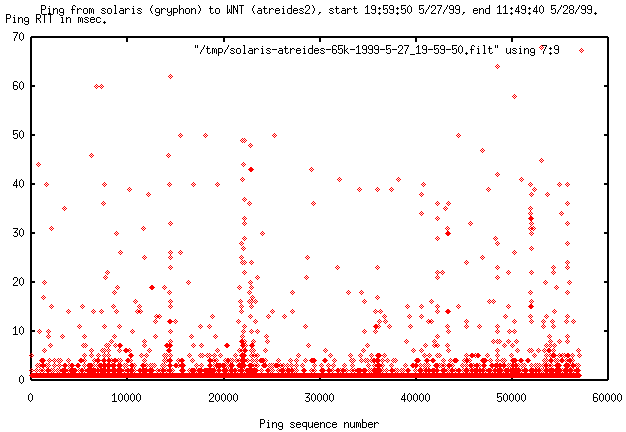
Ping between Linux and Sun (gryphon)
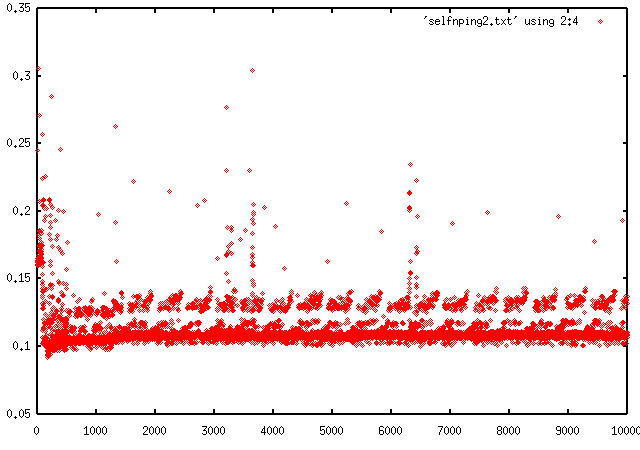
Ping from Linux to self
Network connections
| Host | Switch port | IP address | MAC address | OS |
|---|
| atlas/dhcp-24-179 | CGB3: 3/4 | 134.79.24.179 | 00-10-04-f5-f5-53 | WNT 4/SP4 |
| atreides | CGB3: 3/16 | 134.79.24.12 | 00-c0-4f-76-18-36 | WNT 4/SP4 |
| doris | CGB3: 3/7 | 134.79.24.122 | 00-c04f-98-6b-f7 | Linux Redhat 5.2 |
| eccles | CGB3: 3/16 | 134.79.24.95 | 00-c0-4f-a3-8d-04 | Linux Redhat 5.2 |
| gryphon | CGB3: 3/5 | 134.79.25.130 | 08-00-20-22-ed-4b | Solaris 5.6 |
| hector | CGB3: 3/2 | 134.79.24.97 | 00-60-97-cc-50-26 | WNT 4/SP 4 |
| odin | CGB3:
3/6 | 134.79.24.46 | 00-c0-4f-a3-b8-51 | Linux Redhat 5.2 |
| procrustes | CGB3: 3/8 | 134.79.24.84 | 00-c0-4f-b9-6a-65 | WNT 4/SP4 |
| yemint | CGB3: 3/7 | 134.79..24.86 | 00-c0-4f-c2-77-cd | WNT 4/SP4 |
Possible resolution
On Tuesday July 15, '02 I received the following email from Stephan Bohacek [bohacek@math.usc.edu]:
Hi Les,
We have been doing extensive high frequency ping measurements. We had
noticed a similar effect you noted in
http://www.slac.stanford.edu/comp/net/wan-mon/pathology-eg.html.
However, we have since determined that this is due to the operating
system stalling. For example, our windows machines stalls every 300 ms
for 16 ms. Thus, a packet will be delayed anywhere from 0 to 16 ms
depending how far along the stall is when the packet arrives. Since the
stalling is periodic and the pings are sent periodically, the delay
pattern can be quite complex (as you noted). We have fixed the problem
by using real-time operating systems (RTAI a real time linux).
We are writing up some details. I'll send them on when they are complete.
[ Feedback ]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}